Lossy Compression Basics and Quantization
Recap
In the first half of this course, we learned about lossless compression techniques and the fundamental limits imposed by entropy. We also learnt about the tradeoffs for various entropy coders. Here is a summary:
- Learnt about fundamental limits on lossless compression: entropy,
- Thumb rule:
- Learn about various lossless compressors aka entropy coders and their implementations
- Block codes: Shannon coding and Huffman coding
- Streaming codes: Arithmetic coding and Asymmetric Numeral Systems
- Universal (pattern) matching codes: LZ77
- Learnt about how to deal with non-IID sources
- Context-based coding
- Adaptive coding
Introduction
However, today we want to discuss a different setting. Many real-world data sources such as audio, images, and video are continuous in nature rather than discrete. To represent these sources digitally, we need to approximate and quantize them, which inherently introduces some loss of information. Previously, we assumed a discrete information source that could be losslessly compressed by entropy coding techniques like Huffman or arithmetic coding. The discrete entropy represented a hard limit on the best possible lossless compression. Let's think about a continuous source now. How much information does it contain?
Quiz-1: How much information does a continuous source X contain?
A continuous source contains an infinite amount of information, so it cannot be represented digitally in a lossless manner. This is in-fact related to a fundamental property about real numbers: they are uncountable, i.e., there are infinite real numbers between any two real numbers. Instead, we need to approximate it by quantizing to a discrete representation. This quantization step will inevitably induce some loss or distortion.
The key aspects of lossy compression are:
- It allows some loss of information or fidelity in order to achieve higher compression. The original source cannot be perfectly reconstructed.
- Lossless compression is a special case of lossy compression with zero distortion.
- Quantization is used to convert the continuous source into a discrete representation. This is a fundamental part of lossy compression.
- Entropy coding is still widely applicable and typically used as the final step after quantization.
Lossy Compression Basics: Rate-Distortion Tradeoff
A continuous source contains infinite information, so we cannot represent it exactly. We need to approximate it, which implies some unavoidable loss of information.
Distortion (D) is a quantitative measure of this loss of information introduced by the approximation/quantization process. Common distortion metrics include:
- Mean squared error (MSE):
- Mean absolute error (MAE):
In lossy compression, we have a choice regarding the tradeoff between rate and distortion:
Rate (R) refers to the number of bits used per sample to represent the lossy approximation of the source.
Higher rate implies we can represent the source more accurately with lower distortion D.
Lower rate means we have to tolerate more distortion to achieve higher compression.
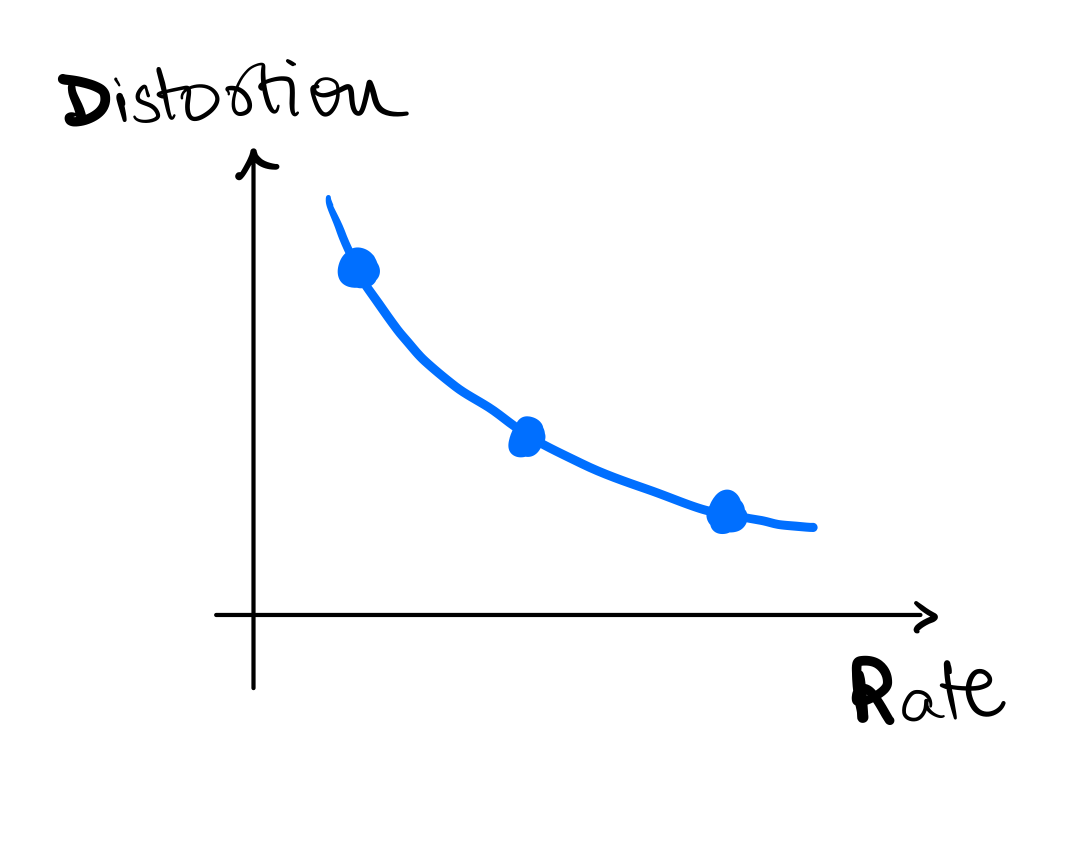
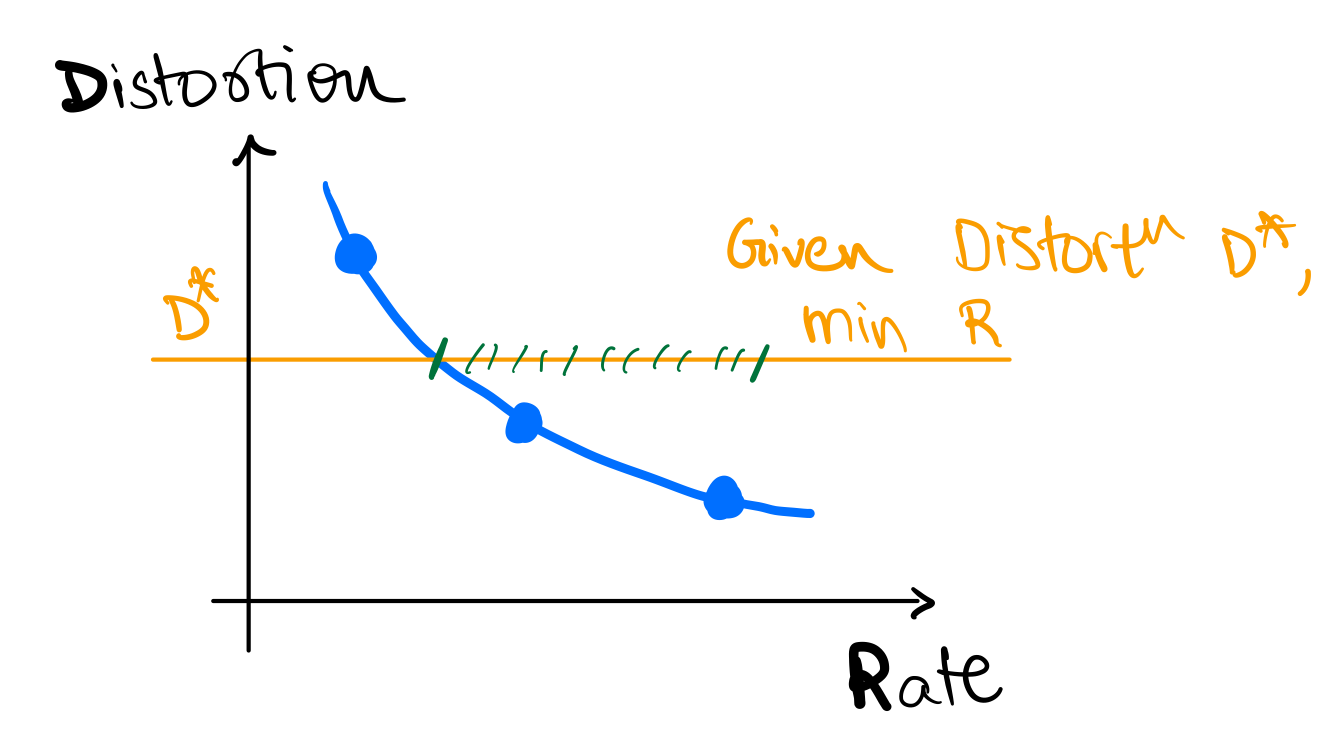
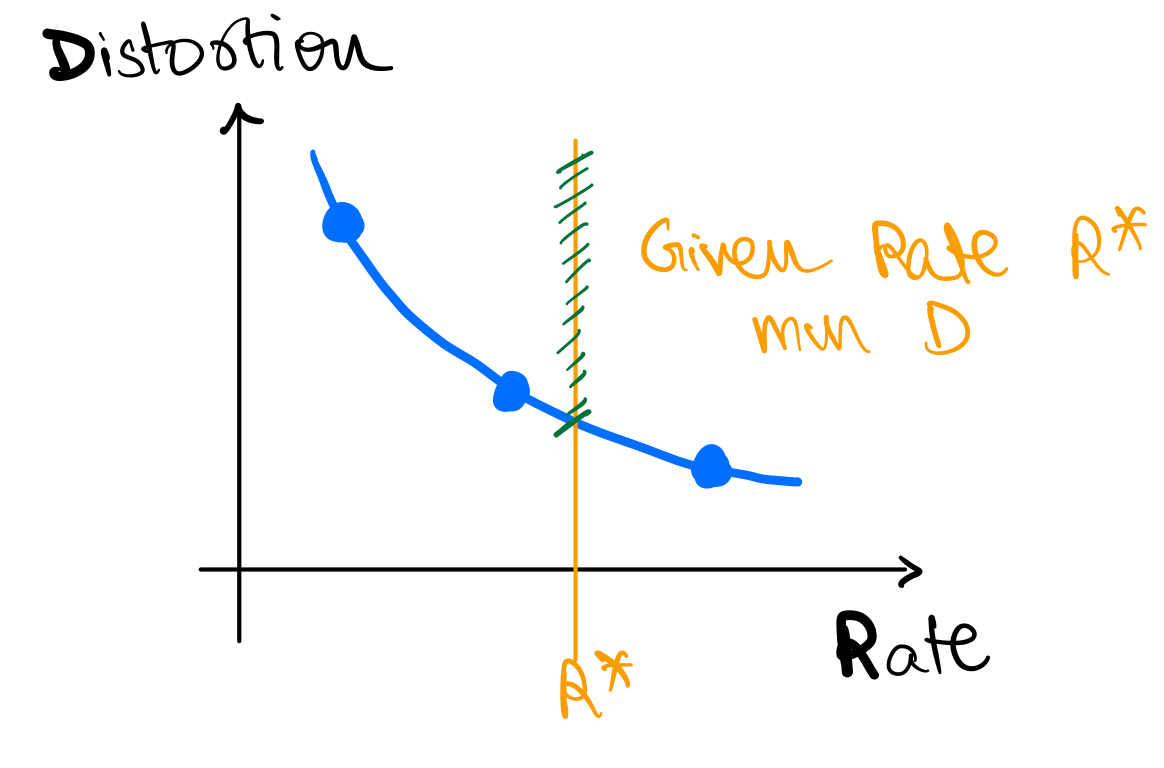
This inherent tradeoff between rate R and distortion D is fundamental to lossy compression and quantization. Figure below shows a cartoon of the rate-distortion tradeoff. Fundamental to this discussion is the fact that we always strive to achieve the best possible rate-distortion tradeoff, i.e.
- given a distortion level (), we want to achieve the lowest possible rate ()
- given a rate (), we want to achieve the lowest possible distortion ()
In next set of notes, we will learn more about the rate-distortion theory which provides a theoretical framework for this tradeoff.
Example
Let's work through an example together.
Example 1
- Let's say you are measuring temperature (
T) in a room, say in Celsius, at an hourly interval.- Remember, physical
Tis a continuous source.
- Remember, physical
- Say your sensor is very sensitive and it records
T = [38.110001, 36.150901, 37.122020, 37.110862, 35.827111]
Quiz-2: How many bits do we want to represent T?
It depends on the application! If we are using it to control the AC, we might need more bits than if we are using it to decide whether to wear hoodie or T-shirt. In either case,
- we need to decide on the distortion we are OK with
- we can agree these many decimals are waste of bits
Quiz-3: What are some reasonable values to encode?
One reasonable way to encode is to round T to the nearest integer, i.e., T_lossy = [38, 36, 37, 37, 35]. This is similar to converting T to int from float.
Quantization
What we did in the previous example is called quantization (or binning).
- Quantization is the process of mapping a continuous source to a discrete source.
- Quantization is a lossy process, i.e., it introduces distortion.
- Quantization is a fundamental operation in lossy compression!
- Quantized values are also sometimes called symbols or codewords, and the set of quantized values is called codebook or dictionary.
- In previous example, codebook is
{35, 36, 37, 38}and codewords for each symbol are{35, 36, 37, 37, 35}.
- In previous example, codebook is
Quiz-4: For a codebook of size N, what is the rate R?
The rate because we have quantized symbols and we need bits to represent each symbol. Alternatively, we can say the quantized value for each symbol can take unique values.
Quantization Example - Gaussian
Example 2
Now say, X is a Gaussian source with mean 0 and variance 1, i.e., . Say we want to represent X using just 1 bit per symbol.
Quiz-5: What are some reasonable values to encode?
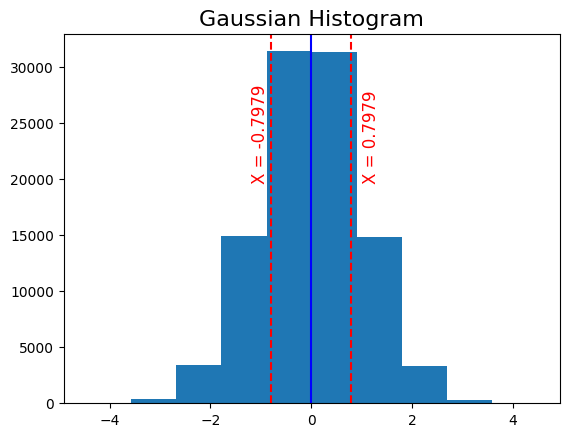
We can decide to convey just the sign of X, i.e., as the distribution is symmetric around 0. Say we get a positive value for , what should be the quantized value of the recovered symbol? For this, we need to decide on the distortion we are OK with. For today's discussion let's say we are concerned about MSE distortion.
Quiz-6: What should be the codebook for this example?
If you have taken signal processing, you know that the conditional expectation of X given the observation is the best linear estimator for MSE distortion. This is called Minimal Mean Square Estimator (MMSE). Mathematically, if we want to find
If you have not seen this before, here are some resources:
Therefore, in our case, the codebook should be .
For gaussian, this is . We can work this out as follows: where the first step follows from definition of conditional expectation and symmetry of gaussian distribution around 0. Similarly, we can show that .
Scalar Quantization
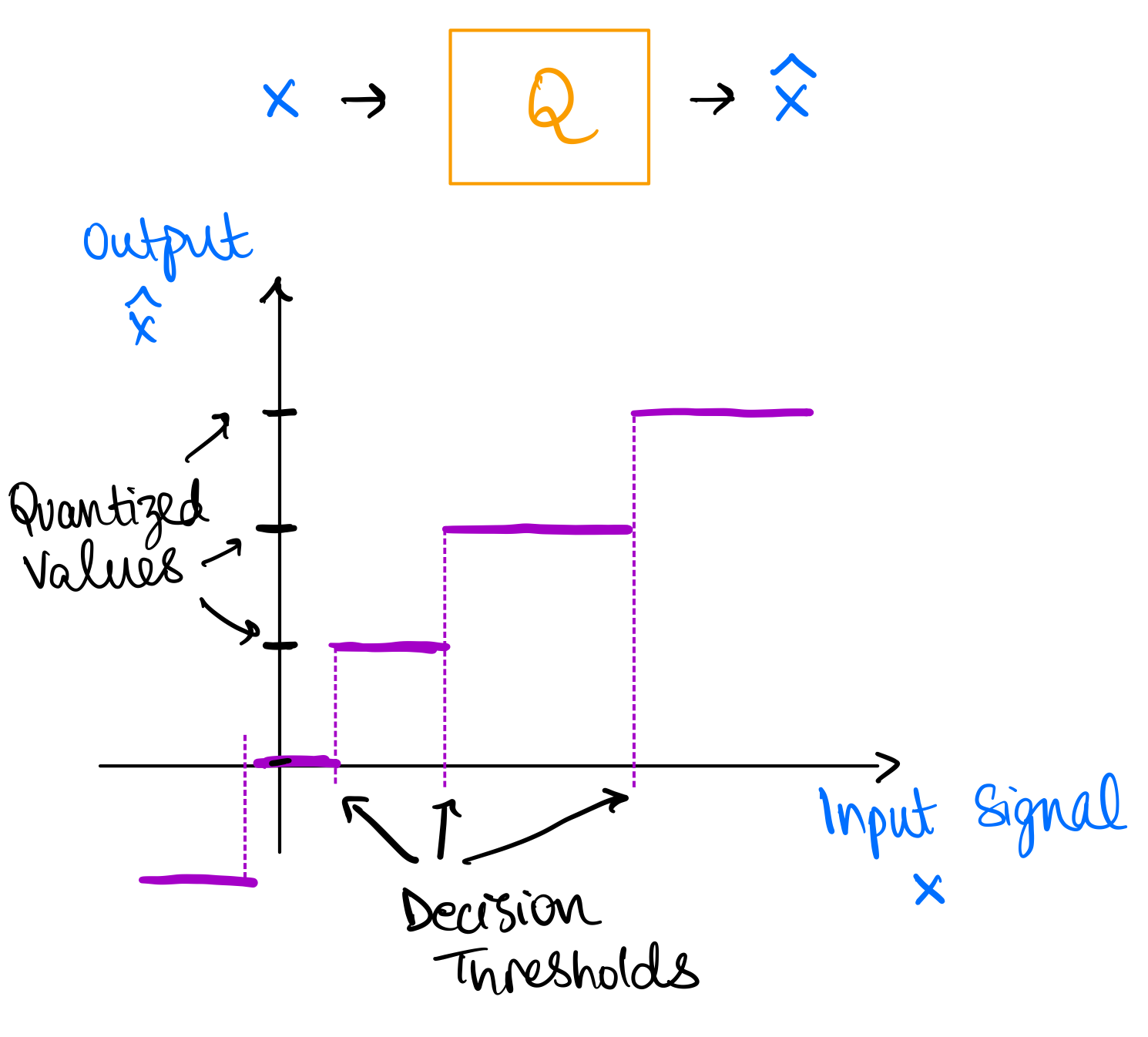
This is an example of scalar quantization. In scalar quantization, we quantize each symbol independently. The figure above explains the process of scalar quantization. Quantization can be thought of as a function which maps continuous symbols to the reconstructed symbols . The quantization function is called quantizer and is denoted by . The quantizer is defined by the codebook , which is the set of quantized values. The quantizer maps each symbol to the nearest quantized value in the codebook, i.e., where is the distortion (or some other distance) metric. The process defines decision thresholds which are the regions where all values of are mapped to the same quantized value in the codebook .
More formally, we can also think of a quantizer as a partition of the input space into disjoint regions such that and for and a mapping from each region to a quantized value .
Vector Quantization
So far, we are quantizing each symbol independently. But can we do better? Maybe we can work with two (or more) symbols at a time? Say we have , where
- you can also think of it as you generated
2*Nsamples from and then split them into two groups of sizeN(similar toblock codesin lossless compression) - or you can think of it as you have two sensors measuring the same source
- or you can think of it as having two sensors measuring two different sources
Quiz-7: We want to compare it with 1 bit/symbol scalar quantization. What's the size of codebook allowed?
The size of the codebook will be . Generalizing, we can have codebook of size for vectors (blocks) of size and bits/symbol. In other words, bits/symbol since we are using quantized values to represent symbols.
More formally, generalizing what we have seen so far,
- A quantizer is a mapping where is the "codebook" or "dictionary" comprising of -dimensional vectors.
- The mapping is defined by: where is a partition of
- The rate is
Vector quantization provides following benefits over scalar quantization:
- We can exploit dependence between vector components
- We can have more general decision regions (than could be obtained via Scalar Quantization)
The image below shows a basic example where vector quantization provides advantage over scalar quantization. Assume you have two dimensional probability density as shown and you want to quantize it. This represents a case where both are uniformly distributed with same sign.
You can either quantize each dimension independently (scalar quantization) or you can quantize both dimensions together (vector quantization). The figure below shows the decision regions for both cases. We take a specific example for vector quantization as shown in the figure. For scalar quantization we have codewords, i.e. and therefore the rate is , whereas for the vector quantizer we only need a strict subset of the scalar quantize codewords requiring half of the codewords, i.e. and therefore the rate is . It is obvious to see here that the distortion for both these quantizers will be same but the rate for vector quantizer is lower.
This is also obvious intuitively! Vector quantization allows us to exploit the correlation between the two dimensions and therefore we can achieve the same distortion with lower rate. It takes advantage of the fact that both dimensions are uniformly distributed with same sign. Therefore, vector quantization provides more flexibility in choosing the decision regions.
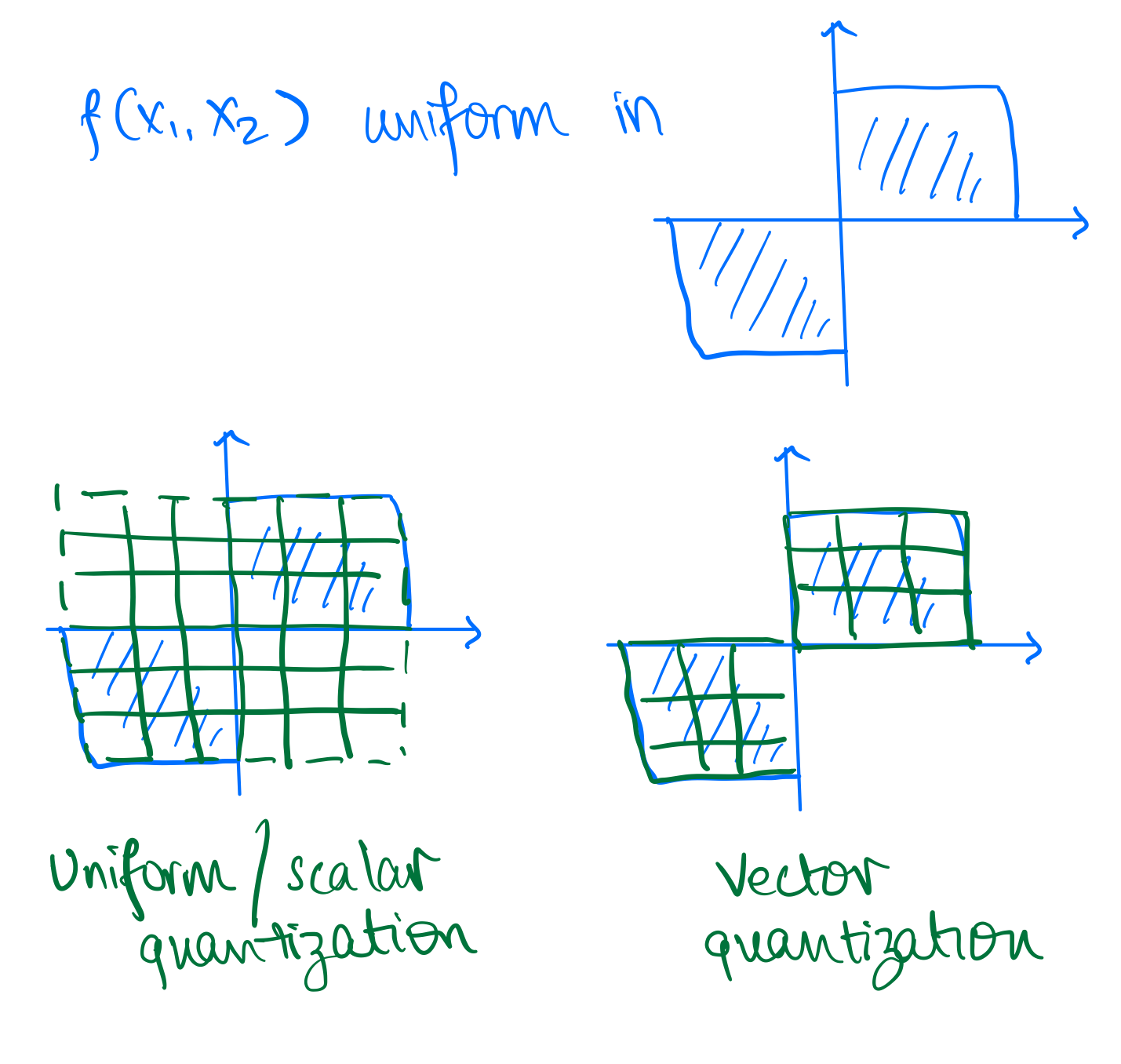
Some additional comments on VQ
Optimal regions are generally not uniform (as in scalar quantization) even in simple uniform IID case! In the 2D case of uniform IID, a hexagonal lattice provides most optimal regions with respect to MSE distortion. This is called lattice quantization or Voronoi diagram and can accommodate more than 2 dimensions. In the case of uniform IID variables in 2D, . This conveys two points to us:
- VQ performs better than SQ even in simple uniform IID case. As seen previously it performs even better in correlated cases.
- This can be a lot of effort for little gain given the source distribution, e.g. in this case we only gain 3.8% in MSE distortion.
Here is a proof for the above result:
Scalar Quantization of each component separately would yield square decision regions of the form as shown in following figure, where is the quantization step size.

The area of the decision region is . Therefore, since we have uniform
Alternatively, we could have chosen a vector quantizer with hexagonal decision regions as shown below:

For this case, using symmetry, the area of the decision region is six times a triangle shown below. Therefore, .
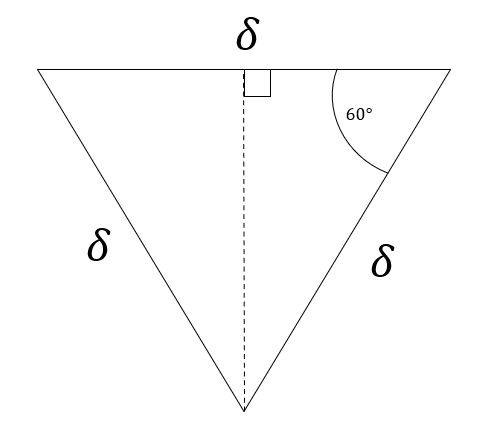
Finding the MSE is left as an exercise to the reader, but it can be shown that
For comparing these two schemes, we will compare them for and such that , so that we have same rate (same number of quantization points covering the same area). This gives us the desired result
Conslusion: Even for a simple uniform IID source, there is benefit in vector quantization over scalar quantization.

The above image is a paper abstract from On universal quantization, Ziv. As you can see under certain conditions, scalar quantization can be competitive with vector quantization. However, in general, vector quantization is better than scalar quantization.
Vector Quantization Algorithm
In general, optimal regions are not easy to compute, and we need to resort to iterative algorithms. Quiz-8: Have you seen this problem before in some other context?
It's same as K-means clustering algorithm in ML! Also called as Lloyd-Max algorithm or Generalized Lloyd algorithm. We want to cluster data points into N clusters corresponding to codebook (k in k-means) such that the average distortion is minimized.
- First proposed by Stuart Lloyd in 1957 (motivated by audio compression) at Bell Labs
- Was widely circulated but formally published only in 1982
- Independently developed and published by Joel Max in 1960, therefore sometimes referred to as the Lloyd-Max algorithm
- Generalized Lloyd specialized to squared error is the Kmeans clustering algorithm widely used in Machine Learning
K-means Algorithm
Given some data points, we can compute the optimal codebook and the corresponding partition of the data points. The main idea is to do each-step iteratively:
- Given a codebook, compute the best partition of the data points
- Given a partition of the data points, compute the optimal codebook
- Repeat until convergence
Here is a pseudocode to illustrate the algorithm:
def k_means(data, k, max_iterations=100):
centroids = initialize_centroids(data, k) # some random initialization for centroids (codebook)
for iteration in range(max_iterations): # some convergence criteria
# Assign data points to the nearest centroid -- this is the partition step
clusters = assign_data_to_centroids(data, centroids)
# Calculate new centroids -- this is the codebook update step
new_centroids = calculate_new_centroids(data, clusters)
# Check for convergence
if np.allclose(centroids, new_centroids):
break
centroids = new_centroids # update centroids
return clusters, centroids
def initialize_centroids(data, k):
# Randomly select k data points as initial centroids
return data[np.random.choice(len(data), k, replace=False)]
def assign_data_to_centroids(data, centroids):
# Assign each data point to the nearest centroid
distances = np.linalg.norm(data[:, np.newaxis] - centroids, axis=2)
clusters = np.argmin(distances, axis=1)
return clusters
def calculate_new_centroids(data, clusters):
# Calculate new centroids as the mean of data points in each cluster
new_centroids = np.array([data[clusters == i].mean(axis=0) for i in range(len(np.unique(clusters)))])
return new_centroids
More resources
Following google colab notebook contains code and additional examples for vector quantization: Notebook
We only scratched the surface of quantization. There are many more advanced topics:
- Constrained vector quantization
- Predictive vector quantization
- Trellis coded quantization
- Generalized Lloyd algorithm
For more details, see following resources:
Next time
We will look into the question of what is the fundamental limit on lossy compression, i.e. what is the best possible rate-distortion tradeoff?