Lossy compression theory
We continue with lossy compression and rate distortion function (Shannon's RD theory) and applications in current technologies.
We'll start with things that seem unrelated but we'll bring it all together towards the end. We'll only touch on some of the topics, but you can learn more in the references listed below and in EE 276.
We'll start with the rate distortion function and see how it carries over to sources with memory. We'll also look into Gaussian sources with memory. Finally, we'll look at the implications to transform coding which is commonly used today.
Reminder from linear algebra:
Consider (matrix vector product)
Then the square of the Euclidean norm (sum of square of components), also denoting the energy in the signal is
In particular, if is a unitary transformation, i.e., all rows and columns orthonormal vectors , then we have This is called the Parseval's theorem which you might have seen for Fourier transform. In words, this says that the energy in transform domain matches the energy in the original.
If and , then . That is to say, unitary transformation preserves Euclidean distances between points.
Lossy compression recap
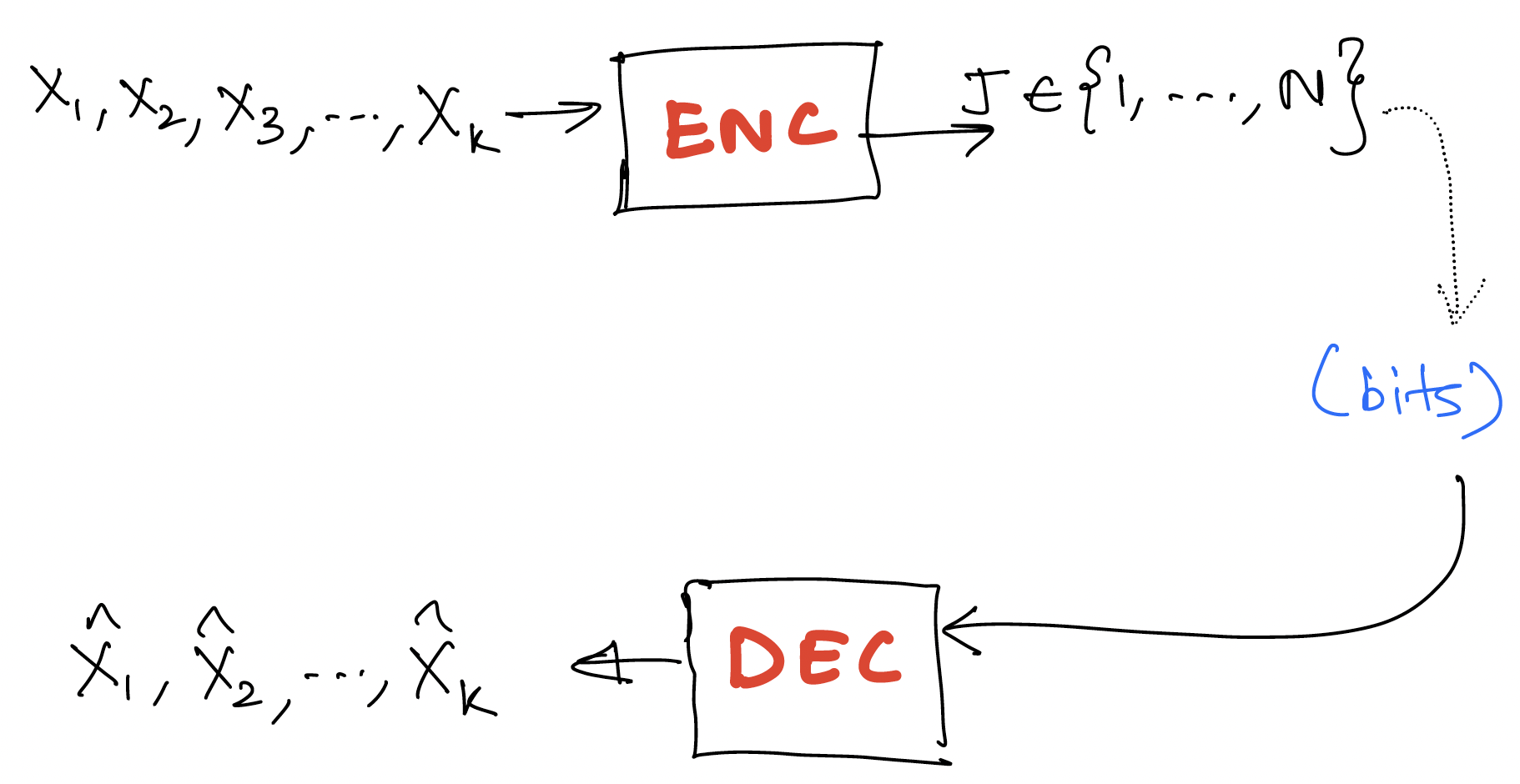
Recall the setting of lossy compression where the information is lossily compressed into an index (equivalently a bit stream representing the index). The decoder attempts to produce a reconstruction of the original information.
The two metrics for lossy compression are:
- bits/source component
- distortion [single letter distortion - distortion between k-tuples defined in terms of distortion between components]
Transform coding
Notation: we denote as which can be thought of as a column vector.
![]()
Here we simply work with an arbitrary transform , with the only requirement being that is invertible and we are able to efficiently compute and . In this framework, we simply apply our usual lossy encoding in the transform domain rather than in the original domain.
In particular, when for some some unitary (e.g., Fourier transform, wavelet transform). Then This corresponds to the squared-error distortion. Any lossy compression you do on , you get the same square error distortion for the original sequence as for the .
Why work in the transform domain? Often in the transform domain, data is simpler to model, e.g., we can construct transform in a way that the statistics of are simpler or we get sparsity. Then we can appropriately design lossy compressor to exploit the structure
Nowadays people even go beyond linear transforms, e.g., learnt transforms using deep learning models. Can even go to a vector in a smaller dimensional space, e.g., in VAE based lossy encoders. This can allow doing very simple forms of lossy compression in the transform domain.
Shannon's theorem recap
For "memoryless sources" ( are iid ~),
We sometimes write to represent this quantity when we want to be explicit about the source in question.
Beyond memoryless sources
Consider source , reconstruction . Then,
Just like was the analog of entropy of , is the analog of entropy of the n-tuple.
Now assume we are working with a process which is stationary. Then we can define . Similar to our study of entropy rate, we can show that this limit exists.
Shannon's theorem for lossy compression carries over to generality. That is, the best you can do for stationary processes in the limit of encoding arbitrarily many symbols in a block is .
Rate distortion for Gaussian sources
Note: For the remainder of this discussion, we'll stick to square error distortion.
Why work with Gaussian sources? It is a good worst case assumption if you only know the first and second order statistics about your source. This holds both for estimation and lossy compression.
For , denote by .
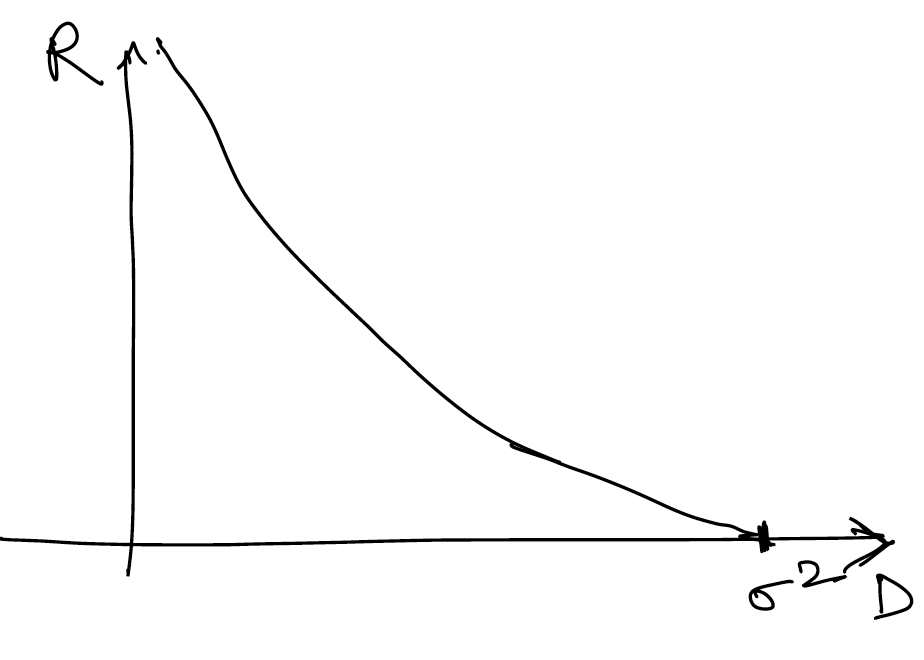
Recall from last lecture that for (above it is just ).
We can compactly write this as , where . This is shown in the figure below.
Similarly for , independent, denote by .
It can be shown that Another way to write this is
Intuition: the result is actually quite simple - the solution is just greedily optimizing the and case (decoupled), and finding the optimal splitting of the distortion between and .
Using convex optimization we can show that the minimum is achieved by a reverse water filling scheme, which is expressed in equation as follows:
For a given parameter , a point on the optimal rate distortion curve is achieved by setting
- for
And the rate given by
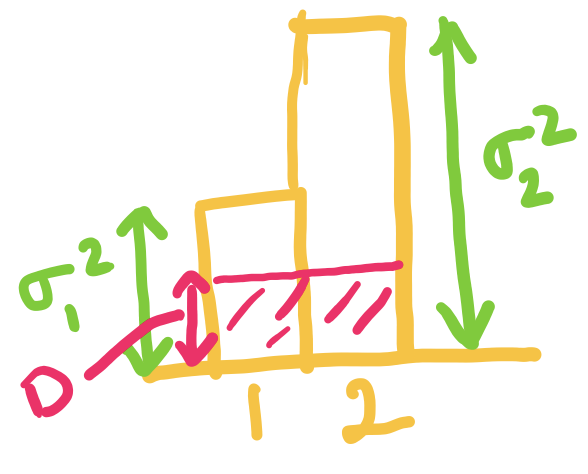
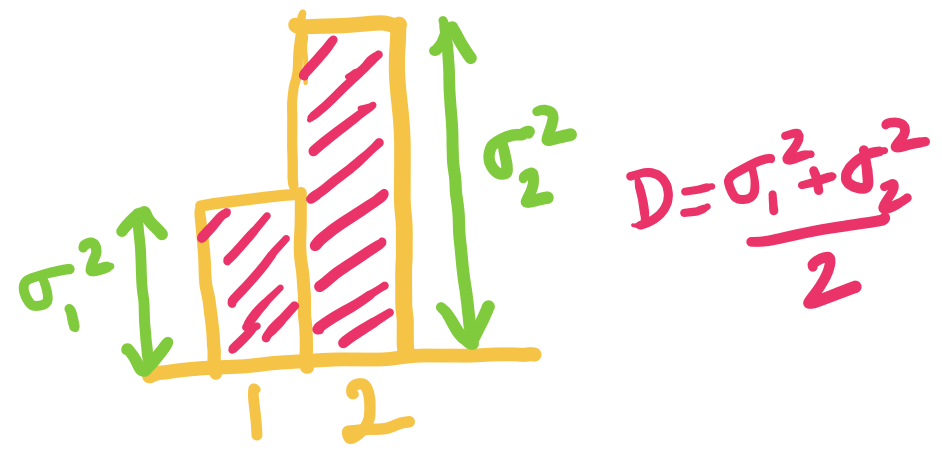
This can be expressed in figures as follows (assuming without loss of generality that ):
When is smaller than both and , we choose both and to be equal to ( in this case). We assign equal distortion to the two components, and higher rate for the component with higher variance.
When exceeds but is below , we set to be , and choose such that the average distortion is . The idea is that setting higher than doesn't make sense since the rate is already for that component.
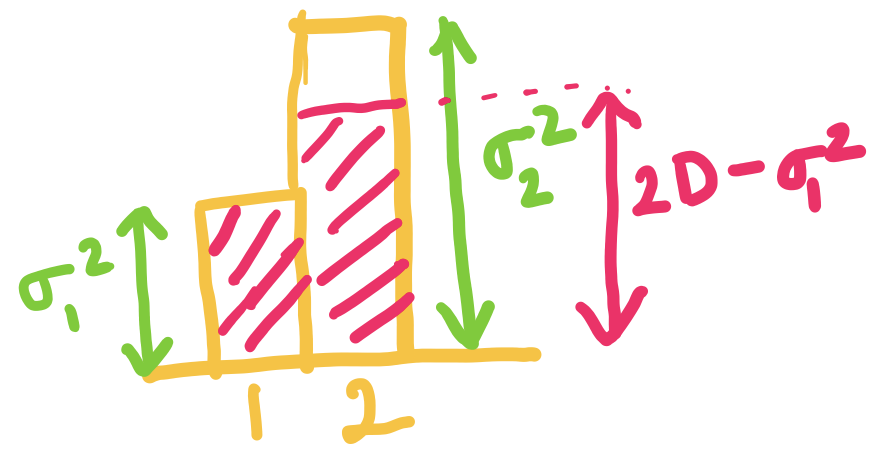
When is equal to we can just set and . Here the rate is for both components!
This generalizes beyond components. For independent with , we define analogously, and can very similarly show that .
Similar to before, the minimum is given by , .
Rate-distortion for stationary Gaussian source
Going back to a process zero mean Gaussian, then for any unitary transformation if then we can show [since the distortion is the same in both domains]. Recall that by using the transformation it's possible to go from a scheme for compressing to a scheme for compressing (and vice versa) without any change in the distortion.
Therefore we can take the diagonalizing unitary matrix which converts to a such that has independent components. The variances of will be the eigenvalues of the covariance matrix.
Thus, we have
where the 's are the eigenvalues of the covariance matix of .
When are the first components of a stationary Gaussian process with covariance matrix for and , with . Then we have where is the vector of eigenvalues of .
Now, we use a theorem to show a profound result for Gaussian processes.
Theorem (Toeplitz distribution) Let be the spectral density of and be a continuous function. Then
Specializing this theorem to and to , we get
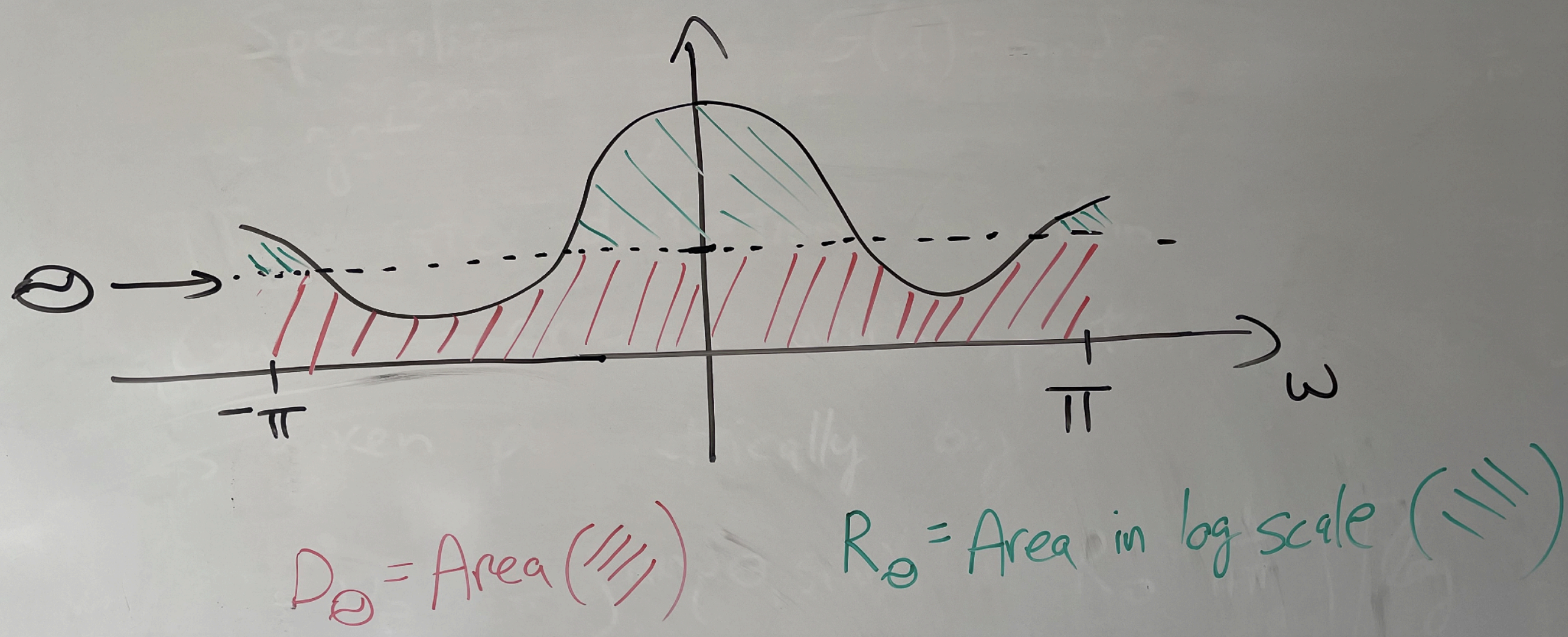
The rate distortion function of a stationary Gaussian process with spectral density is given parametrically by
This is shown in the figure below, suggesting that the reverse water-filling idea extends to Gaussian processes once we transform it to the continuous spectral domain! This gives us motivation for using working in the Fourier transform domain!
Finally, for , we can show that where is the variance of the innovations of . This can be used to justify predictive coding ideas.
Reference
For more details on this, you can read the survey paper "Lossy source coding" by Berger and Gibson available at https://ieeexplore.ieee.org/document/720552.