Quiz Problems (2023)
Here are the quiz problems from the 2023 iteration of the course. Solutions for most of these are discussed in the lectures following the quiz (videos linked in the course website). Solutions for quiz 11, 16 and 17 are provided along with the questions below.
- Quiz 1 (Lossless Data Compression Basics)
- Quiz 2 (Prefix Free Codes)
- Quiz 3 (Kraft Inequality, Entropy)
- Quiz 4 (Huffman Codes)
- Quiz 5 (Asymptotic Equipartition Property)
- Quiz 6 (Arithmetic Coding)
- Quiz 7 (Asymmetric Numeral Systems)
- Quiz 8 (Beyond IID distributions: Conditional entropy)
- Quiz 9 (Context-based AC & LLM Compression)
- Quiz 10 (LZ and Universal Compression)
- Quiz 11 (Lossy Compression Basics; Quantization)
- Quiz 12 (Mutual Information; Rate-Distortion Function)
- Quiz 13 (Gaussian RD, Water-Filling Intuition; Transform Coding)
- Quiz 14 (Transform Coding in real-life: image, audio, etc.)
- Quiz 15 (Image Compression: JPEG, BPG)
- Quiz 16 (Learnt Image Compression)
- Quiz 17 (Humans and Compression)
Quiz 1 (Lossless Data Compression Basics)
Q1 (3 points)
We want to design fixed length codes for an alphabet of size 9.
Q1.1 (1 point)
What is the length in bits/symbol for such a code?
Q1.2 (1 point)
You observe that there is an overhead above due to 9 not being a power of 2. To partially circumvent this, you decide to encode pairs of symbols together, hence effectively working with an alphabet of size 81. What is the length in bits/symbol for a fixed length code applied on blocks of 2 symbols?
Q1.3 (1 point)
Now the alphabet size is 81 because we will be encoding pairs of symbols together, so the length in bits/block is . However, we are encoding blocks of 2 symbols, so the length in bits/symbol is . Did working in blocks of 2 give a better compression ratio?
( ) Yes
( ) No
Q2 (1 point)
Given a random sequence sampled from probability distribution , and the code below, compute the expected code length in bits/symbol.
| Symbol | Codeword |
|---|---|
| A | 0 |
| B | 01 |
| C | 11 |
Quiz 2 (Prefix Free Codes)
Q1 (3 points)
Consider the source with alphabet and probability distribution though . We use a prefix code with codeword lengths , e.g., the construction we saw in class.
Q1.1 (1 point)
Provide the codewords for such a code. Note that your answer need not be unique, just ensure the code is prefix-free and satisfies the lengths above.
Q1.2 (1 point)
Compute the expected code length for this code.
Q1.3 (1 point)
Come up with a prefix code that has a lower expected code length than the one above. Compute the expected length for your code.
Q2 (3 points)
For each of the codes below, is it prefix free?
Q2.1 (1 point)
| Symbol | Codeword |
|---|---|
| A | 00 |
| B | 01 |
| C | 10 |
| D | 11 |
| E | 110 |
( ) Yes
( ) No
Q2.2 (1 point)
| Symbol | Codeword |
|---|---|
| A | 001 |
| B | 011 |
| C | 100 |
| D | 111 |
| E | 110 |
( ) Yes
( ) No
Q2.3 (1 point)
| Symbol | Codeword |
|---|---|
| A | 00 |
| B | 00 |
| C | 10 |
| D | 111 |
| E | 110 |
( ) Yes
( ) No
Quiz 3 (Kraft Inequality, Entropy)
Q1 (5 points)
Recall that a random variable X defined on a binary alphabet is if .
Q1.1 (1 point)
What is the entropy of random variable , i.e.
( )
( )
( )
Q1.2 (1 point)
What is the KL-divergence between distributions and ,
( )
( )
( )
Q1.3 (1 point)
Q1.4 (1 point)
What is ?
Hint: try setting or to .
( ) 1.0
( )
( )
( )
Q1.5 (1 point)
Is for general and ?
( ) Yes
( ) No
Q2 (3 points)
Consider a binary source X with .
Q2.1 (1 point)
If we design a Shannon tree code for this source (i.e. the construction we saw in the class), what is the expected code length ?
Q2.2 (1 point)
What is the entropy of this source?
Q2.3 (1 point)
How suboptimal is Shannon code in this case? Report .
Quiz 4 (Huffman Codes)
Q1: Huffman codes on Bernoulli random variables (4 points)
Recall that a random variable is defined on a binary alphabet such that .
Q1.1 (1 point)
What is the Huffman Code for ?
Q1.2 (1 point)
What is the Huffman Code for ?
Q1.3 (1 point)
State True or False: Using the above Huffman code is the best you can do to encode a source?
( ) True
( ) False
Q1.4 (1 point)
State True or False: Using the above Huffman code is the best you can do to encode a source?
( ) True
( ) False
Q2: Huffman codes on particular realization of a source (4 points)
Assume the following alphabet with corresponding probabilities of occurrence for these symbols being .
Before Huffman solved the optimal prefix-free coding problem, Mahatma Gandhi (no relation!) also came up with another code for these symbols (let's call them Gandhi codes):
- A -> 0
- B -> 10
- C -> 110
- D -> 111
Your friend argues Gandhi's code is better than Huffman's code. For this they generate a random instance of this source and get the symbols .
Q2.1 (1 point)
What is the total length of communicated bitstream for the above random instance using Gandhi codes?
Q2.2 (1 point)
What is the total length of communicated bitstream for the above random instance using Huffman codes for the given source distribution?
Q2.3 (1 point)
True or False: Gandhi codes are optimal code for this source.
( ) True
( ) False
Q2.4 (1 point)
True or False: Gandhi codes are optimal if you had to communicate this particular instance of the source.
( ) True
( ) False
Quiz 5 (Asymptotic Equipartition Property)
Q1: Typical Set Size (2 points)
Consider a binary source with . What is the size of the typical set , in terms of ?
Q2: KL Divergence (3 points)
Consider a source . Zoro knows the distribution of this source and designs a per-symbol Huffman code for to encode a sequence of symbols obtained using this source. However, Luffy doesn't know the distribution of this source and encodes it using a per-symbol Huffman code assuming that the sequence of symbols came from .
Q2.1 (1 point)
How many extra number of bits in expectation (per-symbol) does Luffy need over Zoro to encode a sequence from the above source ?
Q2.2 (1 point)
What is the KL divergence between distributions and specified above?
Q2.3 (1 point)
In the class we learnt that KL divergence is an indicator of the excess code-length for mismatched codes. How do you explain that the two answers above do not match?
Quiz 6 (Arithmetic Coding)
Q1: Code-length vs Code Value (2 points)
Consider a Bernoulli random variable (we have been seeing them a lot in the quizzes so far :)) - where and . Consider sequence of symbols AB and BA, to be encoded using Arithmetic Coding (assume idealized version where the codelength is equal to ).
Q1.1 (1 point)
AB and BA have the same code-length.
( ) True
( ) False
Q1.2 (1 point)
AB and BA have the same output codeword.
( ) True
( ) False
Q2: Arithmetic Decoder (3 points)
Assume a probability distribution over symbols with respective probabilities , , . An arithmetic decoder receives as input bitstream 100111 for an input of length 3. What is the decoded sequence?
Quiz 7 (Asymmetric Numeral Systems)
Q1: rANS encoding (4 points)
Recall the rANS encoding procedure as discussed in class (For reference you can look at Slides 44 and 45 in lecture slides on website to see summary of encoding and decoding steps: https://stanforddatacompressionclass.github.io/Fall23/static_files/L7.pdf)
In this question, we will ask you to encode and decode a sequence. We will be using same symbols as discussed in class for ease.
Say be our symbols with probabilities respectively. You want to encode stream of symbols 2,0,1,0 using rANS.
Q1.1 (1 point)
What's the state value (x) in rANS after symbol 2?
Q1.2 (1 point)
What's the state value (x) in rANS after encoding symbols 2,0?
Q1.3 (1 point)
What's the final state value (x) at the end of encoding stream 2,0,1,0?
Q2: rANS decoding (4 points)
Now we will decode using rANS. We have the same setup as before. Now your decoder knows that the number of symbols are 4 and the final state your decoder received is 117.
Q2.1 (1 point)
What is the value of block_id after running the decode_block for first time?
Q2.2 (1 point)
What is the value of slot after running the decode_block for first time?
Q2.3 (1 point)
What is the first decoded symbol? Note that this corresponds to the last encoded symbol since rANS decoding proceeds in reverse.
Q2.4 (1 point)
What is the updated state value (x) after first step?
Q3: When to use ANS? (2 points)
In which of the following scenarios would you consider using ANS as opposed to Huffman or Arithmetic coding? Select all that apply.
[ ] Your application requires the best compression ratio and you are willing to sacrifice encoding/decoding speeds.
[ ] Your application requires extremely fast encoding/decoding and you are willing to sacrifice compression ratio.
[ ] Your application requires adaptive decoding (i.e., the encoder and decoder need to build a model as they go through the data).
[ ] You care about achieving close-to-optimal compression but also want good speed.
[ ] You are working with a modern processor and want to exploit parallel processing to get higher speeds, while still achieving close-to-optimal compression.
Quiz 8 (Beyond IID distributions: Conditional entropy)
Q1: Entropy for Markov Chain (5 points)
Recall the Markov chain setting we covered in class.
Now, we change it to the following setting
Q1.1 (1 point)
What is ?
Q1.2 (1 point)
What is ?
Q1.3 (1 point)
What is ?
Q1.4 (1 point)
Is this process stationary?
( ) Yes
( ) No
Q1.5 (1 point)
Now consider the chain with the same transition probabilities but the initial distribution modified to the stationary distribution of this Markov Chain which is , i.e. and .
Calculate the entropy rate of this stationary Markov source.
Quiz 9 (Context-based AC & LLM Compression)
Q1: Select the best compressor (2 points)
Which lossless compressor is most suitable under following situations:
Q1.1 (1 point)
You know that the data is roughly 2nd order Markov but do not know the transition probabilities.
( ) context-based arithmetic coding
( ) context-based adaptive arithmetic coding
Q1.2 (1 point)
You know that the data is 3rd order Markov and know the exact distribution.
( ) context-based arithmetic coding
( ) context-based adaptive arithmetic coding
Q2: First order adaptive arithmetic coding (3 points)
Consider first order adaptive arithmetic coding with . The initial counts are set to 1, i.e., .
You are encoding , and assume that for encoding the first symbol you take (padding). Thus, after encoding , you will have and the rest of the counts still . Let be the probability model for this predictor.
Q2.1 (1 point)
What is ?
Q2.2 (1 point)
What is ?
Q2.3 (1 point)
Assuming arithmetic coding uses exactly , what is the encoded size for the sequence ?
Quiz 10 (LZ and Universal Compression)
Q1: LZ77 Decoder (3 points)
Your decoder receives the following output from a LZ77 implementation. Note that your decoder doesn't know the parser which was used to generate this table (and in-fact you can show it's not the same as we have seen in the class) -- e.g., the decoder doesn't know minimum match-length used during generation of this table. In this question we will decode this table step-by-step.
Table:
| Unmatched Literals | Match Length | Match Offset |
|---|---|---|
| AABBB | 4 | 1 |
| - | 5 | 9 |
| CDCD | 2 | 2 |
Q1.1 (1 point)
What is the output string after parsing the first row? Your answer should be the symbols which the decoder outputs (e.g., ABABABABA).
Q1.2 (1 point)
What is the output string after parsing the second row?
Q1.3 (1 point)
What is the output string after parsing the third row?
Q2: LZ77 Encoding (3 points)
You realize that Kedar's last name (TATWAWADI) is a very good example to try LZ77 parsing as covered in class. Pulkit tried to do the LZ77 parsing and obtained the following table. Fill the cells with missing elements.
Partial Table:
| Unmatched Literals | Match Length | Match Offset |
|---|---|---|
| TA | 1 | X1 |
| W | X2 | 3 |
| - | 2 | 2 |
X3 | - | - |
Q2.1 (1 point)
What is match offset X1?
Q2.2 (1 point)
What is match length X2?
Q2.3 (1 point)
What are the unmatched literals X3?
Q3 (2 points)
Consider an English text. Also consider a reversibly transformed version where each byte is replaced with itself plus one. So A becomes B, B becomes C and so on.
Q3.1 (1 point)
Zstd would perform similarly on both the original text and the transformed version.
( ) True
( ) False
Q3.2 (1 point)
A LLM-based compressor trained on English would perform similarly on both the original text and the transformed version.
( ) True
( ) False
Q4 (1 point)
Your company produces a lot of data of a particular kind and you are asked to find ways to efficiently compress it to save on bandwidth and storage costs. Which of these is a good approach to go about this?
( ) Use CMIX since your company deserves the best possible compression irrespective of the compute costs.
( ) Use gzip because LZ77 is an universal algorithm and so it has to be the best compressor for every occasion.
( ) Make a statistically accurate model of your data, design a predictor, and then use a context-based arithmetic coder.
( ) Understand the application requirements, try existing compressors like zstd and then evaluate whether there are benefits to create a domain specific compressor based on an approximate model for the data.
Quiz 11 (Lossy Compression Basics; Quantization)
Q1: Quantization of a Uniform RV (5 points)
You are given samples from a Uniform random variable . We will quantize samples from the random variable under mean-square error (MSE) distortion criteria in the following questions.
Q1.1: Optimal Scalar One-bit Quantizer (1 point)
What are the optimal quantization levels (intervals and reconstruction points) for a scalar one-bit quantizer under MSE distortion?
Q1.2: Distortion under scalar quantizer (1 point)
What is the average distortion per-symbol under the optimal scalar quantization scheme described above?
Q1.3: Vector quantization (1 point)
Now we will use a 2D vector quantizer under MSE distortion which still uses one-bit per symbol. This quantizer takes 2 symbols at a time, represents them as a 2D vector and then uses the optimal 2-bit quantizer.
Which of the following vector quantizer is best in terms of distortion under MSE? Choose all options which have the same lowest expected MSE distortion.
[ ]
[ ]
[ ]
Q1.4: Which is better? (1 point)
Which of the two -- scalar or the best 2D quantizer above, is better for lossy compression of uniformly distributed data? Hint: Remember to compare with respect to bits per symbol.
( ) Scalar
( ) 2D-Vector
( ) Both are equivalent
Solutions
Quiz 11 solutions were not covered in lecture, so here they are!
1.1
Solution: For a one-bit quantizer, we need to divide the interval into two parts and assign a reconstruction point to each. By symmetry, we can argue that the two intervals must be and . Now for the reconstruction points, we need to find a point that minimizes the for the first interval which is simply the mean value (can verify that computing the integral and then finding the minima - in general for a different distortion we are looking for the "median" corresponding to that distortion, for MSE the median is the mean!). Similarly for the second interval the reconstruction point will be .
, Reconstruction points =
1.2
Solution: Let us first compute the integral which evaluates to . Now for our case the distortion will be given by the squared error across the range of from (note that the pdf is simply equal to in this whole range). We can split into two intervals according to the reconstruction point and get Reusing the result we just computed with , we get the answer as
1.3
[ ]
[ ]
[X]
Solution: Here we are trading off between assiging two intervals to each dimension vs. providing all four intervals to a single dimension. We can reuse the result from above for this:
A single interval (zero bits) would have giving us . Two intervals (one bit) would give us giving us . Four intervals (two bits) would give us giving us .
Now we can see that using one bit for each dimension gives us the lowest sum because . Thus the correct option is the third one.
1.4
( ) Scalar
( ) 2D-Vector
(X) Both are equivalent
Solution: Both are equivalent because the 2D quantizer we chose above effectively does optimal scalar quantization with one bit per dimension.
Quiz 12 (Mutual Information; Rate-Distortion Function)
Q1: Calculate Mutual Information (2 points)
You have been given following joint probability distribution table for on binary alphabets:
| P(X=x,Y=y) | y = 0 | y = 1 |
|---|---|---|
| x = 0 | 0.5 | 0 |
| x = 1 | 0.25 | 0.25 |
Q1.1: Joint Entropy (1 point)
Calculate the joint entropy .
Q1.2: Mutual Information (1 point)
Calculate the mutual information .
Q2: Rate-Distortion (2 points)
Consider a uniformly distributed source on alphabet .
You have been asked to lossily compress this source under MSE (mean square error) distortion and have been asked to calculate the rate distortion function for a given distortion value .
Q2.1 (1 point)
What is ?
Q2.2 (1 point)
What is ?
Q3 (1 point)
For a source with Hamming distortion, we saw in class that , where is entropy of a binary random variable with probability . Which of the following are correct? (Choose all that apply)
[ ] There exists a scheme working on large block sizes achieving distortion D and rate < .
[ ] There exists a scheme working on large block sizes achieving distortion D and rate > .
[ ] There exists a scheme working on large block sizes achieving distortion D and rate arbitrarily close to .
[ ] There exists a scheme working on single symbols at a time (block size = 1) achieving distortion D and rate arbitrarily close to .
Quiz 13 (Gaussian RD, Water-Filling Intuition; Transform Coding)
Q1: Reverse water filling (3 points)
Note: The problem appears long, but it's mostly just a recap from class!
Recall the problem of compressing two independent Gaussian sources with means and variances and . For the squared error distortion we saw in class, the rate distortion function is given by
where .
The solution suggests we split the overall distortion between the two components and then use the optimal strategy for each component independently.
We also saw in class that the optimal split into and is given by a reverse water filling idea, which is expressed in equation as follows:
For a given parameter , a point on the optimal rate distortion curve is achieved by setting
for
And the rate given by
This can be expressed in figures as follows (assuming without loss of generality that ):
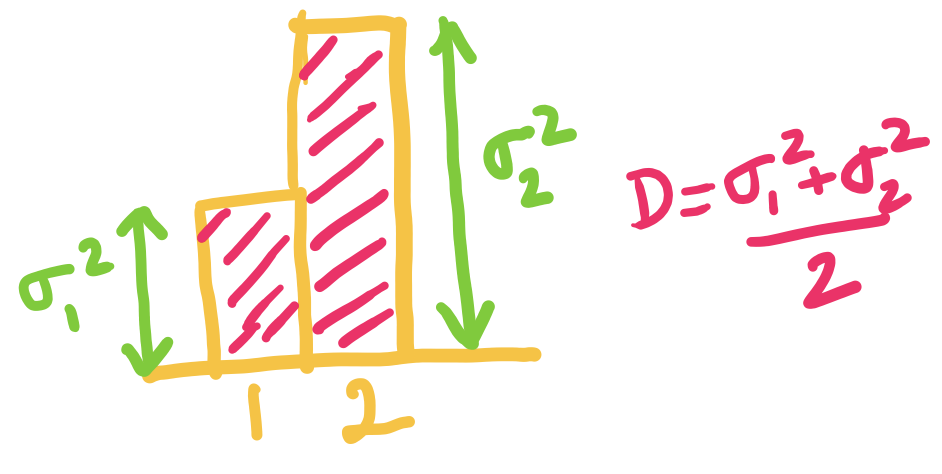
When is smaller than both and , we choose both and to be equal to .
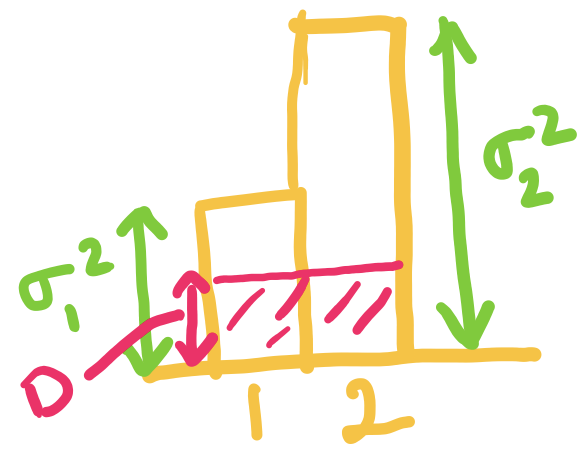
When exceeds but is below , we set to be , and choose such that the average distortion is .
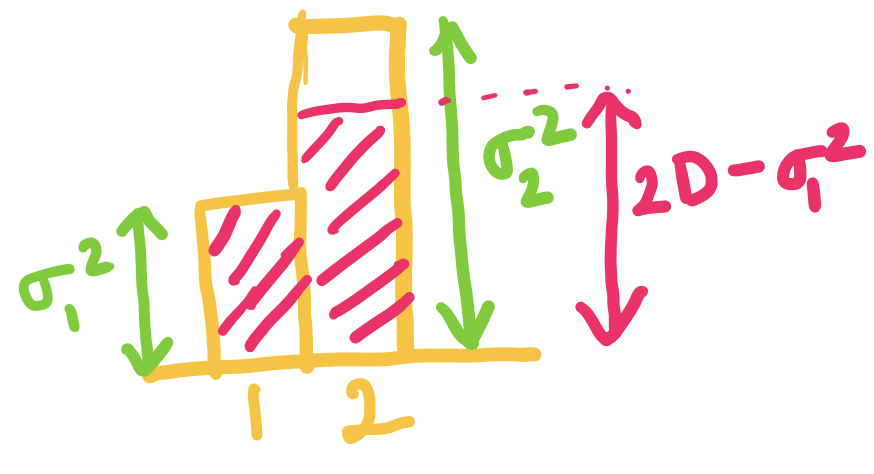
When is equal to we can just set and .
Now consider a setting with and .
Q1.1 (1 point)
At , what are the optimal values of and :
( )
( )
( ) ,
( ) ,
Q1.2 (1 point)
At , what is the optimal rate
( ) bits/source component
( ) bits/source component
( ) bits/source component
( ) bits/source component
Q1.3 (1 point)
Which of the following is correct?
[ ] For below the two variances, we divide the distortions equally among the two components.
[ ] For below the two variances, we use a higher bitrate for the component with higher variance.
[ ] For between the two variances, we use zero bitrate for one of the component.
[ ] For between the two variances, we use zero bitrate for both of the components.
Quiz 14 (Transform Coding in real-life: image, audio, etc.)
Q1 (2 points)
Q1.1: Vector Quantization (1 point)
In which of the following cases do you expect vector quantization to improve the lossy compression performance? (select all the correct options)
[ ] i.i.d. data compressed with scalar quantization
[ ] non-i.i.d. (correlated) data with scalar quantization
Q1.2: Transform Coding (1 point)
In which of the following cases do you expect transform coding to improve the lossy compression performance? (select all the correct options)
[ ] i.i.d. data
[ ] non-i.i.d. (correlated) data
Q2 (3 points)
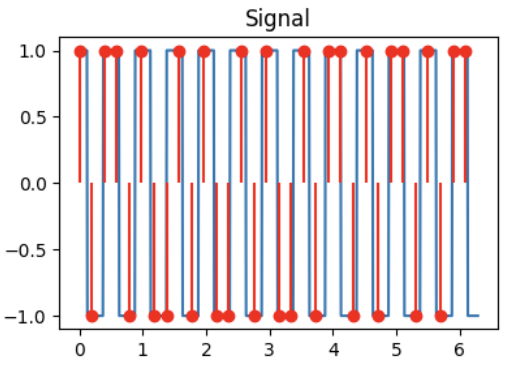
Match the signals to their DCT!
Signal 1
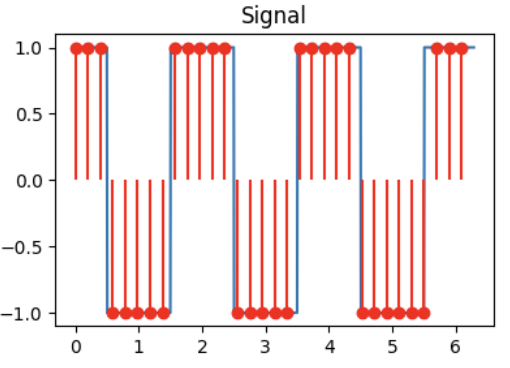
Signal 2
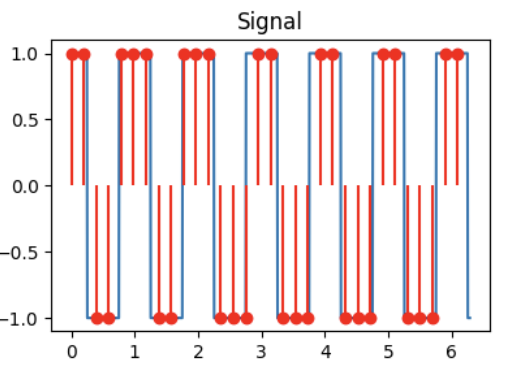
Signal 3
DCT A
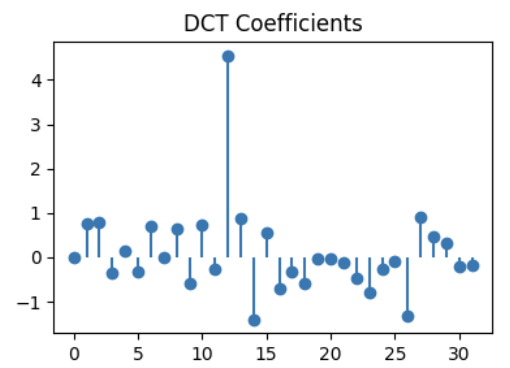
DCT B
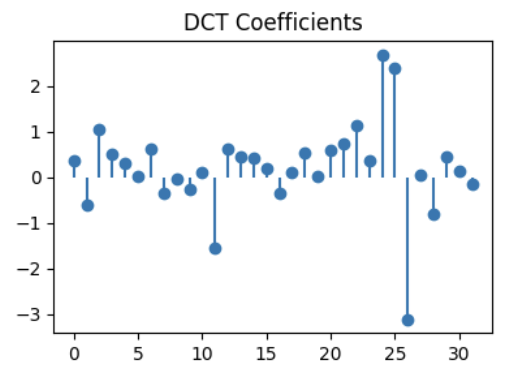
DCT C
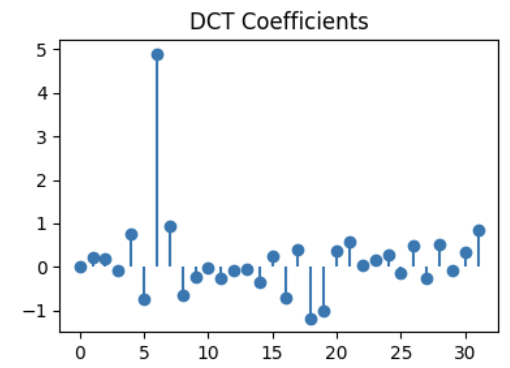
Q2.1 (1 point)
DCT for signal 1:
( ) DCT A
( ) DCT B
( ) DCT C
Q2.2 (1 point)
DCT for signal 2:
( ) DCT A
( ) DCT B
( ) DCT C
Q2.3 (1 point)
DCT for signal 3:
( ) DCT A
( ) DCT B
( ) DCT C
Q3: DCT truncation (1 point)
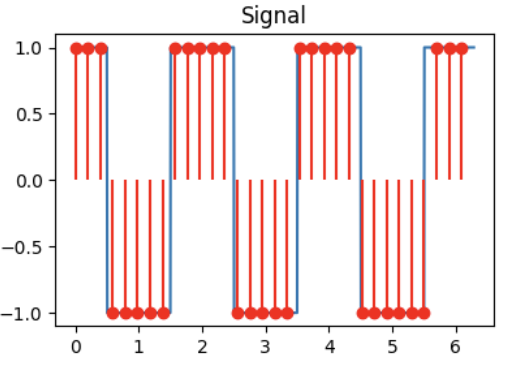
For the signal shown above, we take the DCT and truncate (zero out) the 16 highest frequencies (out of 32 total components in the DCT). Identify the reconstructed signal obtained after performing the inverse DCT.
( ) A
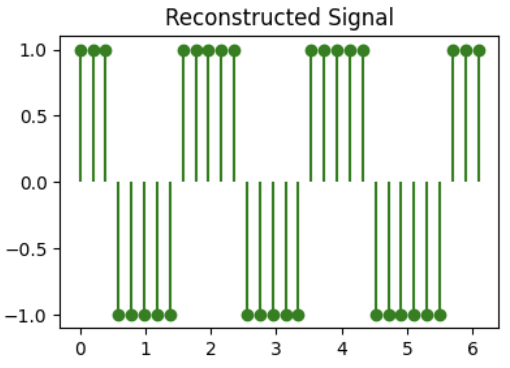
( ) B
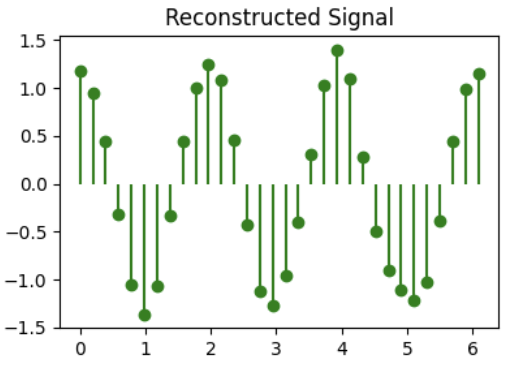
( ) C
Quiz 15 (Image Compression: JPEG, BPG)
Q1: Image Compression (4 points)

Before the next big game, facing an inevitable loss, Berkeley students hacked into Stanford website and tried to mutilate the Stanford logo into a Berkeley blue color version (but did a bad job at it). The mutilated logo is shown as an image above.
This image is of dimensions , and contains channels (RGBA) instead of channels for colors we saw in class. The fourth channel is alpha channel which tells the transparency of the image. The bit-depth of this image is , which basically implies that every pixel in each channel is 8 bits.
This file can be compressed losslessly using PNG to (kilo-bytes).
Q1.1 (1 point)
What's the expected raw size of this image? Leave you answer in KB (note: Kilo Bytes not Kilo bits)
Q1.2 (1 point)
In this image you can see that there are basically just two colors (white and a bad version of Berkeley blue color). What will be the expected image size if we use only 2 colors to compress this image in KB? Note, we assume that you still need 8 bits for the alpha channel.
Q1.3 (1 point)
Now you also see that along with having just 2 colors, the image also has only two levels of transparency (perfectly transparent and perfectly opaque). Using these properties what will be the expected image size in KB?
Q1.4 (1 point)
PNG seems to perform better than even using 1 bit for color and 1 bit for alpha!
Give one reason why this might be the case. Note: there are many reasons! But we are only asking for one so feel free to choose.
Q2: JPEE274G Compressor (4 points)
EE274 students decided to come together and form JPEE274G (Joint Photographers EE 274 Group) coming up with an image compressor with the same name. Help them make the design decisions.
Q2.1 (1 point)
Riding on the compute revolution, JPEE274G decided to go for block size instead of .
Suppose you have the same image at resolution , ,
In which of the following case do we expect increasing the block-size help the the most.
( )
( )
( )
Q2.2 (1 point)
JPEE274G decided to use prediction of blocks based on previously encoded neighbors. In which of the following two images do we expect the prediction to help the most.


( ) Charizard (the one with the orange cranky being)
( ) Assorted Pokémons (the one with Pokemon written in it)
Q3: Predictive Coding (2 points)
You find a source where consecutive values are very close, so you decide to do predictive lossy compression. Encoder works in following fashion: it first transmits the first symbol and after that it quantizes the error based on prediction from last encoded symbol. The quantized prediction error is transmitted.
Formally, suppose is your original sequence and is the reconstruction sequence. Then we have:
- for the first symbol the reconstruction , i.e., you are losslessly encoding the first symbol
- prediction for is simply
- prediction error is
- quantized prediction error is
- reconstruction for is
- the transmitted sequence is
For this question, assume that the quantization for the prediction error is simply integer floor.
Example encoding for source sequence:
| 1 | - | 0.4 | - | - |
| 2 | 0.4 | 1.1 | 0.7 | 0 |
| 3 | 0.4 | 1.5 | 1.1 | 1 |
| 4 | 1.4 | 0.9 | -0.5 | -1 |
| 5 | 0.4 | 2.1 | 1.7 | 1 |
| 6 | 1.4 | 2.9 | 1.5 | 1 |
| 7 | 2.4 | - | - | - |
Q3.1: Errors (1 point)
What is the absolute value of reconstruction error for the last symbol?
Q3.2: Now Decode (1 point)
Given the transmitted sequence = , what is the final decoded value ?
Quiz 16 (Learnt Image Compression)
Q1 (7 points)
Have a look at the notebook we showed in class to answer following questions. The notebook can be found at class website as well as on this link.
Q1.1 (2 points)
We have defined the transforms, but we need to define a training procedure to train these non-linear transforms. We are using the distribution tfp.distributions.Normal(loc=0., scale=1.) as a prior for codelayer y. i.e. we are making the analysis_transform decorrelate input data to unit gaussians.
In which case do you expect the output of estimated_rate_loss(self.prior, y) to be higher:
( ) y=5
( ) y=0
Q1.2 (3 points)
Explain briefly why with unit normal prior for code layer y with latent_dims=50, the bits_used can never go below 50 bits.
Hint: take a look at the prior distribution on the integers on slide 41 here.
Bonus: can you think of a tighter lower-bound?
Q1.3 (2 points)
Which of the following would you expect to reduce the rate where the loss function is . Select all that apply.
[ ] increase
[ ] decrease
[ ] increase the latent space dimension
[ ] decrease the latent space dimension
Solutions
(X) y=5
( ) y=0
Solution: Note that the rate loss is defined as the negative log probability of the quantized Gaussian probability distribution, and hence y farther away from 0 gives us lower probability and hence higher rate.
-
Solution: The best you can do in terms of bits used is to have all the quantized latent variables be 0 (since that has the highest probability). Looking at the figure, we see the probability is below 0.4 so the number of bits used by arithmetic coder is more than log2(1/0.4) ~ 1.32 bits/latent dimension. Thus we will not go below 50 bits and a tighter bound would be 50*1.32=66 bits.
[ ] increase
[X] decrease
[ ] increase the latent space dimension
[X] decrease the latent space dimension
Solution: Lower gives lower emphasis on distortion and hence the training will lead to a model with higher distortion but lower rate. Decreasing the latent space dimension will also reduce the rate (in particular it will reduce the lowest rate you can achieve as you have seen in the previous question).
Quiz 17 (Humans and Compression)
Q1: MSE vs. L1 error vs. visual perception (1 point)
Recall the distortion functions MSE (mean square error) and L1 distortion (mean absolute error). Which of the following is always true?
( ) Lower MSE implies better visual perception
( ) Lower L1 implies better visual perception
( ) None of the above
Q2: Chroma subsampling (2 points)
In which of the following settings will chroma subsampling typically lead to most noticeable artifacts? (select all that apply)
[ ] Landscape image (natural images have low spatial frequencies)
[ ] Text image (say screenshot of wikipedia page)
[ ] Cartoon/Animated Content (note cartoons are artificially generated and have sharp edges)
[ ] Videos (note videos have temporal variance in noise along with spatial variance)
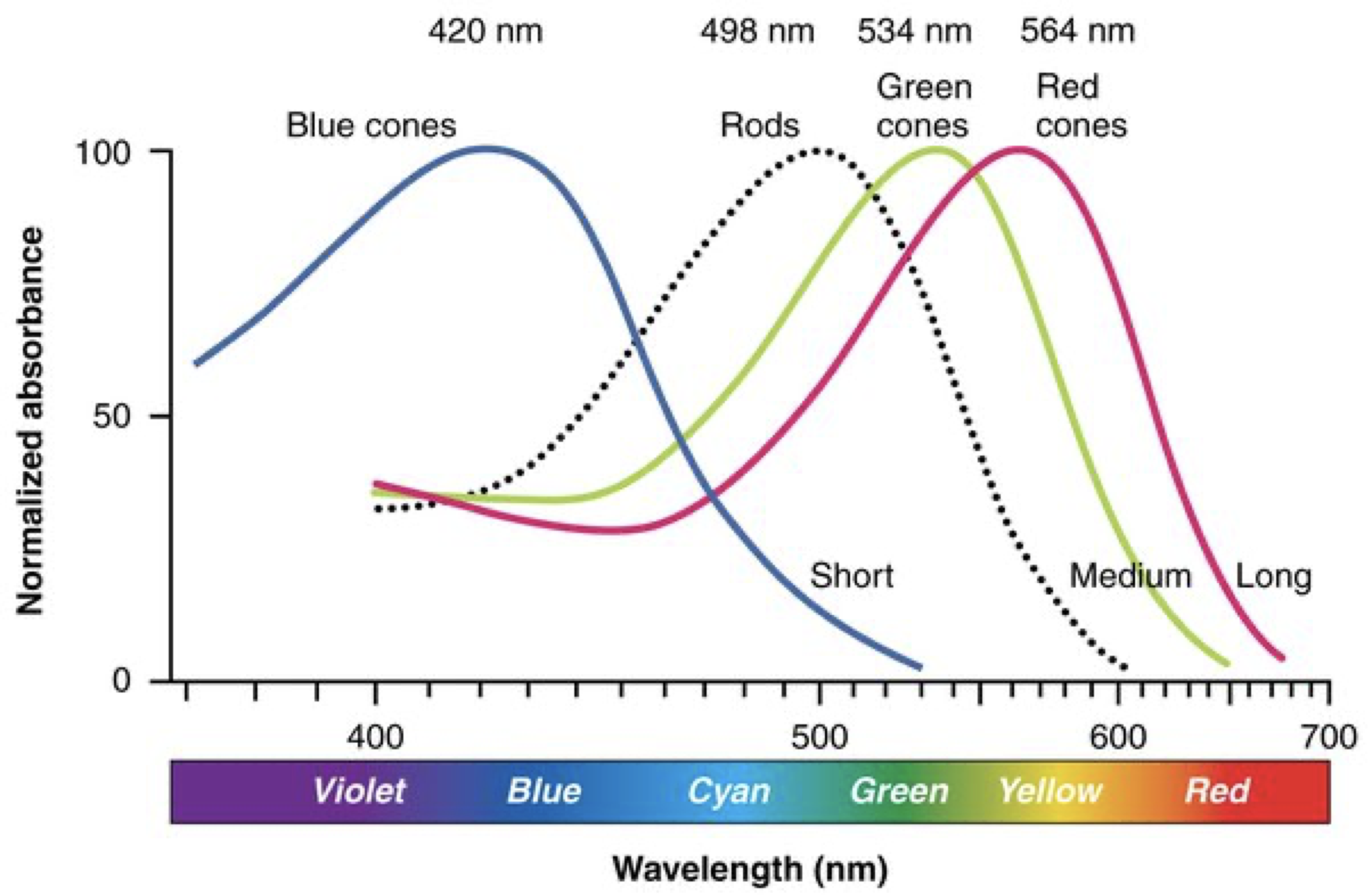
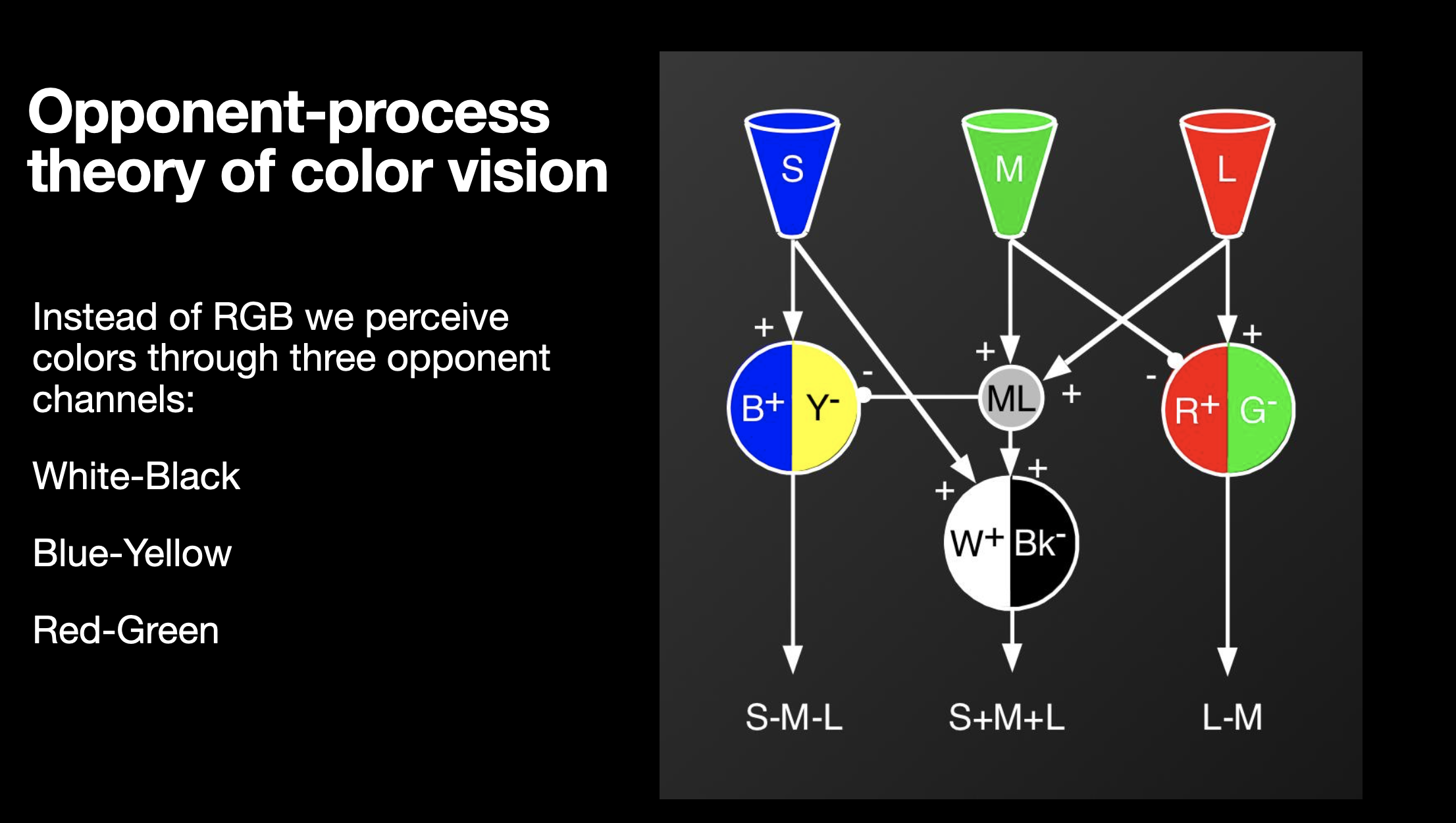
Q3: YCbCr matrix (4 points)
Look at the images we saw in class on color-space below. Recall that Y represents luminance or white/black opponent channel, Cb represents blue/yellow and Cr represents red/green color channel. It might be helpful to know that yellow can be represented as a combination of red and green. Answer the following questions:

A student comes up with a new colorspace conversion recommendation for RGB to YUV conversion. Which of the following matrices are possibly correct color conversions: (select all that apply)
[ ]
[ ]
[ ]
[ ]
Solutions
Q1
( ) Lower MSE implies better visual perception
( ) Lower L1 implies better visual perception
(X) None of the above
Solution: Neither MSE nor L1 are an accurate estimate of visual perception.
Q2
[ ] Landscape image (natural images have low spatial frequencies)
[X] Text image (say screenshot of wikipedia page)
[X] Cartoon/Animated Content (note cartoons are artificially generated and have sharp edges)
[ ] Videos (note videos have temporal variance in noise along with spatial variance)
Solution: As seen in class, chroma subsampling produces significant artifacts when you have a lot of sharp edges like in text/screenshot and cartoons.
Q3
Solution: Only the first matrix is correct. In each of the other options, one of the rows doesn't represent the proper meaning of the YCbCr components. For example in the second option, the third row corresponding to Cr has R-B instead of R-G.