EE274 (Fall 25): Homework-2
- Focus area: Lossless Compression
- Due Date: Oct 28, midnight (11:59 PM)
- Weightage: 15%
- Total Points: 115 (Written 85 + Programming 30)
Q1: Camping Trip (20 points)
During one of the camping trips, Pulkit was given rope segments of lengths by Kedar, and was asked to join all the ropes into a single long segment of length . Pulkit can only join two ropes at a time and the "effort" in joining ropes with length and using a knot is . Pulkit is lazy and would like to minimize his "effort" to join all the segments together.
For instance, consider , and . One could first combine and leading to an effort of , followed by combining and with effort of . This corresponds to a total effort of . On the other hand, if one combines and first, that would lead to a first step cost of , and total effort of . Thus the first approach in this example would lead to a lower total effort.
-
[5 points] Do you see any parallels between the problem and one of the prefix-free codes you have learnt about? Please justify your answer.
Solution
Yes, the problem is connected to
Huffman Codes. The cost of joining a rope into the final segment is proportional to number of times it is used in the knotting process. We will need to pay a larger penalty for a rope if it is used for creating a knot earlier, than later. We can visualize the process of creating the final long segment as a prefix-free tree construction where nodes represent the cost of joining the ropes and depth of the node indicates how many times the particular rope corresponding to this node was used for creating the final segment. Mathematically, the problem is same aswhere is the length of the rope and is the number of times the rope is knotted.
We have seen this optimization problem before in class when we were constructing
Huffman tree! -
[5 points] Let be the optimal (minimal) value for the effort required to join all the segments. Without solving the problem, can Pulkit get an estimate of what the would be? Provide a lower bound and an upper bound as a function of the rope lengths.
Solution
To map the problem precisely to Huffman Tree construction as seen in class, we need to ensure that we are optimizing over probability distribution over ropes. This can be trivially done by normalizing the rope lengths. Let be the probability corresponding to Huffman tree for rope . Then, the problem can be mapped to the following optimization problem:
Note that is constant given rope-lengths. We can now use the fact that the optimal value of the above optimization problem is equal to the entropy of the probability distribution over ropes scaled by the sum of rope-lengths. Therefore,
where is the entropy of the probability distribution over ropes as defined above.
-
[10 points] Implement the function
compute_minimum_effort()in the filehw2_p1.py.
HINT: One way to solve this is to use one of the prefix-free code implementations in the SCL Library. You may import it under TODO section.Solution
def compute_minimal_effort(rope_lengths_arr: List[float]) -> float: """ rope_lengths_arr -> list of rope lengths (positive floating points) output -> the value of the minimum effort in joining all the ropes together """ effort = 0 ########################################################### # ToDo: add code here to compute the minimal effort ########################################################### # raise NotImplementedError from scl.compressors.huffman_coder import HuffmanTree from scl.core.prob_dist import ProbabilityDist # create a prob_dist out of the rope_lengths_arr rope_lengths_dict = {f"rope_id_{ind}": val for ind, val in enumerate(rope_lengths_arr)} prob_dist = ProbabilityDist.normalize_prob_dict(rope_lengths_dict) encoding_table = HuffmanTree(prob_dist).get_encoding_table() # compute minimal effort as the average codelength of huffman code effort = 0 for rope_id in encoding_table: effort += len(encoding_table[rope_id]) * rope_lengths_dict[rope_id] ########################################################### return effort
Q2: Generating random non-uniform data (25 points)
Consider the problem of sampling a non-uniform discrete distribution, given samples from a uniform distribution.
Let's assume that we are given a single sample of random variable U, uniformly distributed in the unit interval [0,1) (e.g. U = numpy.random.rand()). The goal is to generate samples from a non-uniform discrete distribution . We will assume that is a rational distribution. i.e. for any symbol , , where are integers.
-
[5 points] Given a non-uniform rational distribution, we can sample a single random value from
Uby finding the cumulative distribution bin in which the sampleUfalls since the cumulative distribution also lies between[0,1). For example, if is the distribution such asP = {A: 2/7, B: 4/7, C: 1/7}, then we output the symbolsA,B,Cbased on the intervals in which they lie as follows:if U in [0.0, 2/7) -> output A if U in [2/7, 6/7) -> output B if U in [6/7, 1.0) -> output CGeneralize the above algorithm to any given rational distribution, and describe it in a few lines. For a distribution of alphabet size (e.g. in the example above), what is the time/memory complexity of your algorithm wrt ?
Solution
We can use the cumulative distribution function to find the bin in which the sample
Ufalls and output the sample corresponding to that bin. The cumulative distribution function is defined as: . We can find the bin in which the sampleUfalls by finding the smallest such that and then output symbolx. We can usebinary searchfor finding the bin. The time complexity of this algorithm is , where is the size of the alphabet. The memory complexity is , since we need to store the cumulative distribution function. -
[5 points] Complete the function
generate_samples_vanillainhw2_p2.pywhich takes in a non-uniform rational distributionPand returnsdata_sizenumber of samples from it. You can assume that the distribution is given as a dictionary, where the keys are the symbols and the values are the frequency of occurrence in the data. For example, the distributionP = {A: 2/7, B: 4/7, C: 1/7}can be represented asP = Frequencies({'A': 2, 'B': 4, 'C': 1}). Ensure that your code passes thetest_vanilla_generatortest inhw2_p2.py. Feel free to add more test cases.Solution
def generate_samples_vanilla(freqs: Frequencies, data_size): """ Generate data samples with the given frequencies from uniform distribution [0, 1) using the basic approach :param freqs: frequencies of symbols (see Frequencies class) :param data_size: number of samples to generate :return: DataBlock object with generated samples """ prob_dist = freqs.get_prob_dist() # some lists which might be useful symbol_list = list(prob_dist.cumulative_prob_dict.keys()) cumul_list = list(prob_dist.cumulative_prob_dict.values()) cumul_list.append(1.0) generated_samples_list = [] # <- holds generated samples for _ in range(data_size): # sample a uniform random variable in [0, 1) u = np.random.rand() ############################################### # ADD DETAILS HERE ############################################### # NOTE: side="right" corresponds to search of type a[i-1] <= t < a[i] bin = np.searchsorted(cumul_list, u, side="right") - 1 s = symbol_list[bin] generated_samples_list.append(s) ############################################### return DataBlock(generated_samples_list) -
[5 points] Given a single sample of a uniform random variable
U, how can you extend your algorithm in part2.1above to sample i.i.d random values ? Provide a concrete algorithm forP= {A: 2/7, B: 4/7, C: 1/7}. Generalize your method to an arbitrary number of samples and describe it in a few sentences.Solution
We can sample i.i.d random values by first calculating the cumulative distribution corresponding to all possible symbols of block length
nand then following the procedure as described above. Note this method scales very poorly withnsince the size of the alphabet increases exponentially withn. -
[5 points] Pulkit suggested that we can slightly modify Arithmetic Entropy Coder (
AEC) we learnt in the class to sample a potentially infinite number of i.i.d samples given any rational distribution from a single uniform random variable sampleU! You can look at Pulkit's implementationgenerate_samples_aecinhw2_p2.pyto get an idea of how to exploitAEC. Can you justify the correctness of Pulkit's method in a few lines?Note: Even though we say that we can sample potentially infinite number of samples, in practice we are limited by the precision of floats.
Solution
Pulkit's solution first samples a random number
Uin and then truncates it to 32 bits. Then it artificially considers the truncated sample as the output of an arithmetic encoder coming from data with same probability as distribution we want to sample from. Finally, it outputs a random bit sequence based on the output of arithmetic decoding on this encoded bitstream. The scheme works because we know that the probability of the uniform random variable lying in an interval in is proportional to the interval length and an arithmetic encoder-decoder pair works by dividing the number line between in interval lengths proportional to the probability of corresponding n-block symbols. Therefore, we can recover an arbitrarynbit symbol (upto precision of floats) with correct probabilities as given distribution by simply using arithmetic encoding followed by arithmetic decoding. -
[5 points] Now let's say that you have to sample data from a Markov distribution . Recall for a Markov Chain, . Can you use your technique from
Q2.3or the technique suggested by Pulkit inQ2.4to sample any number of samples with Markov distribution from a single uniform random variable sampleU in [0,1)? Describe the algorithm in a few lines.Solution
We can use either of the techniques in
Q2.3orQ2.4to sample from a markov chain by simply modifying the probability distribution of n-block symbols to be the markov chain distribution. For example, we can use technique inQ2.3by calculating the cumulative distribution corresponding to all possible symbols of block lengthnusing the described markov chain probability decomposition and then following the procedure as described inQ2.3. We can use technique inQ2.4by considering the truncated sample as the output of an arithmetic encoder coming from data with same probability as markov chain distribution we want to sample from. In this case, we'll use the conditional distribution at each arithmetic decoding step as we did in lecture 9.
Q3: Conditional Entropy (20 points)
In this problem we will get familiar with conditional entropy and its properties.
We learnt a few properties of conditional entropy in class:
We will use these properties to show some other useful properties about conditional entropy and solve some fun problems!
-
[5 points] Let be an arbitrary function which maps to a discrete set . Then show that: . Can you intuitively explain why this is the case? Make sure to provide both theoretical proof and intuitive explanation.
Solution
Given a value of , has a deterministic value . Therefore and
-
[5 points] Show that , i.e. processing the data in any form is just going to reduce the entropy. Also, show that the equality holds if the function is invertible, i.e. if there exists a function such that . Can you intuitively explain why this is the case? Make sure to provide both theoretical proof and intuitive explanation.
Solution
Let's use the chain rule of entropy in two different ways:
since and . Therefore, .
The equality holds when . This holds when is a deterministic function of implying that is invertible. Intuitively, if there is a one-to-one mapping between and , then the entropy of is the same as the entropy of as all we are doing is changing the alphabets but not the probability distribution across those alphabets!
-
[4 points] In the HW1 of the 2025 edition of EE274, Pulkit and Shubham had an assignment to compress the Sherlock novel (let's call it ). Pulkit computed the empirical
0thorder distribution of the letters and used those with Arithmetic coding to compress , and received average codelength . While working on the assignment, Shubham accidentally replaced all letters with lowercase (i.eA -> a,B -> betc.). Let's call this modified text . Shubham compressed with the same algorithm as Pulkit, and got average codelength . Do you expect , or . Justify based on properties of Arithmetic coding andQ3.2.Solution
We know that . Since Shubham replaced all capital letters with lowercase, the operation can only reduce the entropy, i.e. . We also know that arithmetic coder achieves entropy of any given probability distribution, and hence, .
-
[6 points] We say that random variables are pairwise independent, if any pair of random variables are independent. Let be three pairwise independent random variables, identically distributed as . Then show that:
- [3 points] . When is equality achieved?
- [3 points] . When is equality achieved?
Solution
Using chain rule of entropy and the fact that are pairwise independent, we have:
where since and are independent. But note that, need not be always as our random variables are pairwise independent but need not be mutually independent! Third line follows from the fact that are and hence .
a. To show this note that: , since conditioning reduces entropy. This equality is achieved when is independent of and , i.e. random variables are mutually independent.
b. To show this note that: , since entropy is always positive. FromQ1.1this equality is achieved when is a function of . Since the marginal distribution of is , you can show that only function which satisfies this property is . -
[NOT GRADED, THINK FOR FUN!] Let be i.i.d random variables. Then show that using the , you can generate pairwise independent random variables, identically distributed as .
Solution
Consider all possible xor combinations of , i.e. . We can see that each of these random variables are pairwise independent since are i.i.d. and . Hence, we can generate pairwise independent random variables, identically distributed as .
Q4: Bits-Back coding and rANS (45 points)
In class, we learnt about rANS. We started with the basic idea of encoding a uniform distribution on {0, ..., 9} (see Introduction section in notes) and then extended it to non-uniform distributions. In this problem we will look at a different way of thinking about rANS, which will help us understand the modern entropy coder.
Let's start by first generalizing our idea of encoding a uniform distribution on {0, ..., 9} to a uniform distribution on {0, ..., M-1}, where M can be thought of as number of symbols in the alphabet. The encoding works as following:
def encode_symbol(state, s, M):
state = (state * M + s)
return state
The encoder maintains a single state, which we increase when we encode a symbol. Finally, we save the state by simply writing it out in the binary form. This function is implemented in hw2_p4.py as UniformDistEncoder.
-
[2 points] Write a
decode_symbolpseudocode which takes in the encoded statestateandMand returns the symbolsand the updated statestate. Show that your decoder along with above encoding is lossless, i.e. we can recover the original symbolsfrom the encoded statestateandM.Solution
def decode_symbol(state, M): s = state % M state = state // M return s, stateSince the state input into the decoder is
state = state_prev * M + swith0 <= s < M, then(state_prev * M + s) % M = s. Therefore, we can recover the original symbolsfrom the encoded state state andM. And the previous state is then just(state_prev * M + s) // M. -
[3 points] Show that given data in
{0, ..., M-1}, the encoder/decoder pair can be used to achieve lossless compression with~ log2(M)bits/symbol as we encode large number of symbols.Solution
Just like in the case where
M=10we discuss in the course notes, the size of the state increases by a factor ofMfor every symbol we encode, plus an addition ofs. After some time, thissterm will be small relative to the state, which is several powers ofMlarger, so in the limit of a large number so symbols, we can ignore thesterm. and the number of bits required to encode the state islog2(M)times the number of symbols encoded. -
[5 points] Now, implement your decoder in
hw2_p4.pyasUniformDistDecoder. Specifically, you just need to implementdecode_opfunction. Ensure that your code passes thetest_uniform_codertest inhw2_p4.py. Feel free to add more test cases.Solution
def decode_op(state, num_symbols): ''' :param state: state :param num_symbols: parameter M in HW write-up :return: s, state_prev: symbol and previous state ''' s = state_prev = None #################################################### # ADD CODE HERE # raise NotImplementedError #################################################### s = state % num_symbols state_prev = state // num_symbols # Make sure you use integer operations and not float operations to avoid precision issues! assert np.issubdtype(type(s), np.integer) assert np.issubdtype(type(state_prev), np.integer) return s, state_prev
Now, we want to implement a compressor which works well for non-uniform data. We will use the base encode/decode functions from UniformDistEncoder, UniformDistDecoder and approach this problem from a new perspective. In class, we learned for any two random-variables and . We will use this property to encode the data . Note that this identity implies
Interpreting this intuitively, it should be possible to encode data X in the following two steps:
a. Encode X,Z together using a joint distribution P(X,Z). Assuming an ideal compressor, this will require H(X,Z) bits.
b. Decode Z|X from the encoded state using distribution P(Z|X). Again, assuming an ideal compressor, this lets us recover H(Z|X) bits.
Step b gives you an intuition for the question name -- bits-back! Here Z is an additional random variable, typically latent variable (latent means hidden).
Be careful while reading this step, as it is not a compressor for X but a decompressor for Z|X! This compressor assumes knowledge of X and decodes Z from the encoded state.
More concretely, we will have an encoder-decoder pair which will work as follows:
def encode_symbol(state, X):
state, Z = decode_zgx(state, X) # decode Z|X from state; knows X. returns Z and updated state.
state = encode_xz(state, (X, Z)) # use this Z, and known X, to encode X,Z together. returns updated state.
return state
def decode_symbol(state):
state, (X, Z) = decode_xz(state) # decode X,Z from state. returns X,Z and updated state.
state = encode_zgx(state, Z, X) # encode Z|X by updating state; knows X. returns updated state.
return state, X
Note that how the encode step now involves both a decoding and an encoding step from another compressor! This is one of the key idea behind bits-back coding. We will now implement the above encoder/decoder pair for non-uniform data.
To see the idea, let's work out a simple case together. As usual let's assume that the non-uniform input is parametrized by frequencies freq_list[s] for s in {1,..,num_symbols} and M = sum(freq_list). For instance, if we have 3 symbols A,B,C with probabilities probs = [2/7, 4/7, 1/7], then we can think of frequencies as freq_list = [2,4,1] and M = 7.
We can also create cumulative frequency dict as we saw in class, i.e. cumul = {A: 0, B: 2, C: 6}.
We will assume Z to be a uniform random variable in {0, ..., M-1}. Then, we can think of X as a function of Z as follows:
def X(Z):
for s in symbols:
if cumul(s) <= Z < cumul(s) + freq_list[s]:
return s
i.e. X is the symbol s such that Z lies in the interval [cumul(s), cumul(s)+freq_list[s]). This is shown in the figure below for the example above.
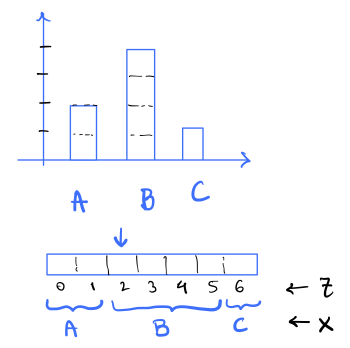
For example if Z = 4, then X = B as cumul(B) = 2 <= 4 < 6 = cumul(B) + freq_list[B].
-
[2 points] What are the values of in the above example?
Solution
Notice that if and otherwise. If , then the term in the sum is also , and if , then , and the term also disappears, since this is true for all terms in the sum, . In general, for some variable, , for any function . This is because f(Y) is completely determined by , so given , there is no uncertainty in and the entropy is 0.
-
[3 points] What is the distribution and entropy of given , i.e. and in the above example? Note that is a function of
xand hence you need to report it for each symbolxin the alphabetA,B,C.Solution Notice that given a value of , is uniformly distributed over the range of . So,
This means that the conditional entropy for is just that of a uniform distribution over 2, 4, and 1 possibilities, respectively. So,
(bonus) The full calculation of is shown below:
Now, let's implement the encoder/decoder pair for the above example. We will use the following notation:
stateis the encoded statesis the symbol to be encoded (X)freq_listis the list of frequencies of the symbols- We want to code the above scheme utilizing the joint compressors over
X, Z(whereZis the latent variable).Zis uniformly distributed in{0, ..., M-1}.combined_symbolis the joint random variableY = (X, Z). In our example, we only need to encodeZasXis a deterministic function ofZ, i.e.combined_symbol = Zand will be in{0, ..., M-1}. For above example, say we want to encodeY = (B, 4), then we only need to encodeZ = 4asX=Bis implied.fake_locator_symbolis the value ofZ|X=xrelative tocumul(x). This is a function ofX=x. For above example ofX = B,Z|X=Bcan be{2, 3, 4, 5}and hencefake_locator_symbolcan be{0, 1, 2, 3}respectively ascumul(B) = 2.- Therefore,
combined_symbolandfake_locator_symbolallows us to have encoder/decoder pair for both(X,Z)andZ|X. Continuing our example, if we were to encodeY = (X=B, Z=4), we will encode it ascombined_symbol = 4andfake_locator_symbol = 2. Conversely, if we were to decodecombined_symbol = 4, we will decode it asY = (Z=4, X=B)and infer thatfake_locator_symbol=2.
-
[5 points] We have implemented the
encode_symbolfunction forNonUniformDistEncoder. Looking at the pseudocode above and the example, explain briefly how it works. Specifically, explain howencode_symbolachieves the relevantdecode_zgxandencode_xzfunctions given in pseudocode in the context of example above.Solution encode_symbol is shown below:
def encode_symbol(self, x, state):
'''
:param x: symbol
:param state: current state
:return: state: updated state
'''
# decode a "fake" uniform sample between [0, freq[x]]
fake_locator_symbol, state = decode_op(state, self.freq.freq_dict[x])
# print(s, fake_locator_symbol, state)
# create a new symbol
combined_symbol = self.freq.cumulative_freq_dict[x] + fake_locator_symbol
# encode the new symbol
state = encode_op(state, combined_symbol, self.freq.total_freq)
# print(state)
# print("*" * 5)
return state
By using decode_op from our UniformDistDecoder, we can decode a "fake" uniform sample between [0, freq[x]]. We then add this to the cumulative frequency of x to get the value of Z, which we encode as combined_symbol (see the first bullet point above). We can now encode the state, encode_op with the value of Z being used for s. decode_zgx is accomplished by the first two lines where we pass the function the state and the value of X and decode Z (which is stored as combined_symbol), and update the state. Then, encode_xz is accomplished by the last line by feeding encode_op the state, Z and X.
-
[10 points] Now implement the
decode_symbolfunction forNonUniformDistEncoder. You can use theencode_opand thedecode_opfrom uniform distribution code. Ensure that your code passes thetest_non_uniform_codertest inhw2_p4.py. Feel free to add more test cases.Solution
def decode_symbol(self, state): ''' :param state: current state :return: (s, state): symbol and updated state ''' ################################################# # ADD CODE HERE # a few relevant helper functions are implemented: # self.find_bin, self.freq.total_freq, self.freq.cumulative_freq_dict, self.freq.freq_dict, self.freq.alphabet # Step 1: decode (s, z) using joint distribution; (i) decode combined symbol, (ii) find s # Step 2: encode z given s; (i) find fake locator symbol, (ii) encode back the fake locator symbol # You should be able to use encode_op, decode_op to encode/decode the uniformly distributed symbols # decode combined symbol combined_symbol, state = decode_op(state, self.freq.total_freq) cum_prob_list = list(self.freq.cumulative_freq_dict.values()) decoded_ind = self.find_bin(cum_prob_list, combined_symbol) s = self.freq.alphabet[decoded_ind] # find fake locator symbol fake_locator_symbol = combined_symbol - self.freq.cumulative_freq_dict[s] # encode back the fake locator symbol state = encode_op(state, fake_locator_symbol, self.freq.freq_dict[s]) ################################################# return s, state -
[5 points] Show that for a symbol
swith frequencyfreq[s], the encoder uses~ log2(M/freq[s])bits and is hence optimal.Solution
For a symbol,
s, the functionencode_symbol(s,state)first divides the input state byfreq[s]in the linefake_locator_symbol, state = decode_op(state, self.freq.freq_dict[s]). Then, the state is multiplied byMin the linestate = encode_op(state, combined_symbol, self.freq.total_freq). So, in each step of the encoding, we scale byM/freq[s], so in the limit of a large number of symbols, we requirelog2[M/freq[s]]bits to encode a state. The expected number of bits per symbol under the true distribution is therefore equal to the entropy of the source, which makes the encoder optimal.
Great, we have now implemented a bits-back encoder/decoder pair for a non-uniform distribution. Let us now see how it is equivalent to rANS we studied in class. As a reminder, the rANS base encoding step looks like
def rans_base_encode_step(x,s):
x_next = (x//freq[s])*M + cumul[s] + x%freq[s]
return x_next
-
[5 points] Justify that
encode_symbolinNonUniformDistEncoderperforms the same operation as above.Solution Let's walk through the transformation of the state in
encode_symbolstep-by-step. First off,fake_locator_symbol, state = decode_op(state, self.freq.freq_dict[s])proforms the transformationstate -> state // freq[s]and givesfake_locator_symbol = state%freq[s]. Then the linestate = encode_op(state, combined_symbol, self.freq.total_freq)performs the transformationstate // freq[s] -> (state // freq[s])*M + combined_symbol, butcombined_symbol = self.freq.cumulative_freq_dict[s] + fake_locator_symbol = cumul[s] + state%freq[s], so overall we havestate -> (state // freq[s])*M + cumul[s] + state%freq[s]. This is exactly the same as the rANS base encoding step, soencode_symbolperforms the same operation as the rANS base encoding step.
Similarly, as a reminder, the rANS base decoding step looks like
def rans_base_decode_step(x):
# Step I: find block_id, slot
block_id = x//M
slot = x%M
# Step II: Find symbol s
s = find_bin(cumul_array, slot)
# Step III: retrieve x_prev
x_prev = block_id*freq[s] + slot - cumul[s]
return (s,x_prev)
-
[5 points] Justify that
decode_symbolinNonUniformDistEncoderperforms the same operation as above.Solution
combined_symbol = state % Mandstate = state//M, socombined_symbol = slotandstate = block_id. Thendecoded_ind = self.find_bin(cum_prob_list, combined_symbol)ands = self.freq.alphabet[decoded_ind]implements = find_bin(cumul_array, slot). Finally,state = encode_op(state, fake_locator_symbol, self.freq.freq_dict[s])performs the transformationstate -> state*freq[s] + fake_locator_symbol, butfake_locator_symbol = combined_symbol - self.freq.cumulative_freq_dict[s], so we havestate -> (state//M)*freq[s] + state % M - cumul[s]for the whole function, which is the same as the rANS base decoding step.
Therefore, bits-back coding is equivalent to rANS! Thinking again in terms of , it allows us to interpret rANS in terms of latent variables in a more intuitive way. This question was highly motivated by the IT-Forum talk by James Townsend in 2022.