EE274 (Fall 25): Homework-4
- Focus area: Lossy compression
- Due Date: 12/02, Tue, midnight (11:59 PM)
- Weightage: 15%
- Total Points: 120
Q1: Mutual Information and Rate Distortion (20 points)
-
[5 points] Consider random variables and and let be an arbitrary function applied to . Show that When does equality hold?
Note: This is a special case of the data-processing inequality, which more generally holds whenever form a Markov chain (i.e., and are conditionally independent given ) and says that . Intuitively, this says that no processing of , deterministic or random, can increase the information that contains about . You can't boost information about contained in just by processing it further!
Solution Because conditioning reduces entropy, we have We also have because and are conditionally independent given (implying that which implies the equality). This is because is a function of so knowing it does not provide any additional information about that cannot already provide.
Thus, we have . Using the definition of mutual information:
Since and entropies are always positive, this implies that . The same proof can be used for the more general case for the data-processing inequality.
Equality holds when , which happens when and are conditionally independent given . Intuitively, this means that captures all the information about that is present in . For example, if then choosing will give equality since the square of can be determined from its absolute value.
-
[15 points] Consider a source which we wish to lossily compress. The reconstruction is allowed to take values in where represents an erasure symbol. The distortion function is given by In words, erasures incur a distortion of , but making a mistake is not allowed (infinite distortion).
a. [10 points] Show that for .
Hint: You can first show that under the condition . Can you relate to ?
Solution For in the feasible set where we have where:
- the first line just uses the definition of mutual information.
- the second line expands the conditional entropy.
- the third line uses the fact the distortion for flipping the bit is infinite and hence for finite distortion given or , is uniquely determined.
- the fourth line uses the fact that is binary and hence .
- the last inequality is due to the fact that here (since the distortion is whenever and otherwise it must be (same logic as point 3)). Thus, .
Can we find a joint distribution in the feasible set that will satisfy the two inequalities with equality? The following construction does the job: let be independent of , and let be given by if and otherwise. More explicitly, we set and . The symmetry makes sure that , and the choice of probabilities makes sure that .
b. [5 points] Suggest a simple and efficient scheme for some finite block size which achieves the optimal rate-distortion performance for this setting. You can assume that is rational, and may choose an appropriate value of accordingly.
Hint: You can start working with a simple example where and the optimal rate is , i.e. you encode two input bits into a single codeword bit.
Solution Since is rational, we can find block length such that and are integers. The scheme to achieve optimal rate-distortion performance is quite simple: the encoder transmits the first bits (hence the rate is bits/input symbol). The decoder fills the remaining positions with erasure , hence achieving distortion of .
Q2: Vector Quantization (20 points)
We have studied vector quantization (VQ) in class. In this question we will first implement part of vector quantization and then study the performance of vector quantization for a correlated gaussian process.
-
[10 points] Implement the
build_kmeans_codebook()method invector_quantizer.py. You cannot use the existing kmeans implementations for this part (e.g.build_kmeans_codebook_scipy()method) and must implement your own version. You can use the methods pre-implemented invector_quantizermodule. It will be instructive to look at the provided test cases in the module. Ensure that the test casetest_vector_quantizationpasses on the provided data. You can use the following command to run the test cases:py.test -s -v vector_quantizer.py -k test_vector_quantizationSolution
def build_kmeans_codebook( data_npy, num_vectors, dim, max_iter=100 ): """ data_npy -> [N] sized numpy array, where N is input data num_vectors -> number of vectors to add dim -> dimension in which to add the vectors max_iter -> the maximum number of iterations to run K-means for (you may terminate early if the vectors converge) output codebook -> [num_vectors,dim] numpy array Also, the expected output should be similar to build_kmeans_codebook_scipy (might not be exact same, due to initialization randomness) """ ##################################################### # ADD DETAILS HERE ###################################################### # NOTE: initializing codebook to zeros as a placeholder # (added here to inform the expected return shape) codebook = np.zeros((num_vectors, dim)) data_npy_2d = np.reshape(data_npy, [-1, dim]) # TODO: add code here to set the codebook appropriately # using K-means. # NOTE: don't directly call scipy/numpy library func # which directly gives out K-means (duh) # NOTE: You may use mse(v1, v2), and find_nearest(codebook_npy, data_vector_npy, dist_func) # functions data_npy_2d = np.reshape(data_npy, [-1, dim]) # TODO: add code here to set the codebook appropriately # using K-means # get random codebook codebook_start_indices = np.random.choice(data_npy_2d.shape[0], size=num_vectors, replace=False) for i in range(len(codebook_start_indices)): codebook[i, :] = data_npy_2d[codebook_start_indices[i], :] # do iterations for i in range(max_iter): vecs_in_codebook = {j: [] for j in range(num_vectors)} for k in range(data_npy_2d.shape[0]): distances = [mse(codebook[j, :], data_npy_2d[k, :]) for j in range(num_vectors)] nearest_codeword = distances.index(min(distances)) vecs_in_codebook[nearest_codeword].append(data_npy_2d[k, :]) # recompute mean for j in range(num_vectors): if len(vecs_in_codebook[j]) == 0: continue else: cumul = np.zeros((1, dim)) for v in vecs_in_codebook[j]: cumul += v / len(vecs_in_codebook[j]) codebook[j, :] = cumul ##################################################### return codebook -
[10 points] Now we use the VQ to encode a correlated source. Consider a simple gaussian process where the second term is independent of , and
Below we visualize the Rate-Distortion performance as well as encoding complexity for different values of (block sizes) and (parameter in the gaussian process), for a given rate of
1 bits per symbol. Based on these plots and what we have learnt in the class, answer following questions: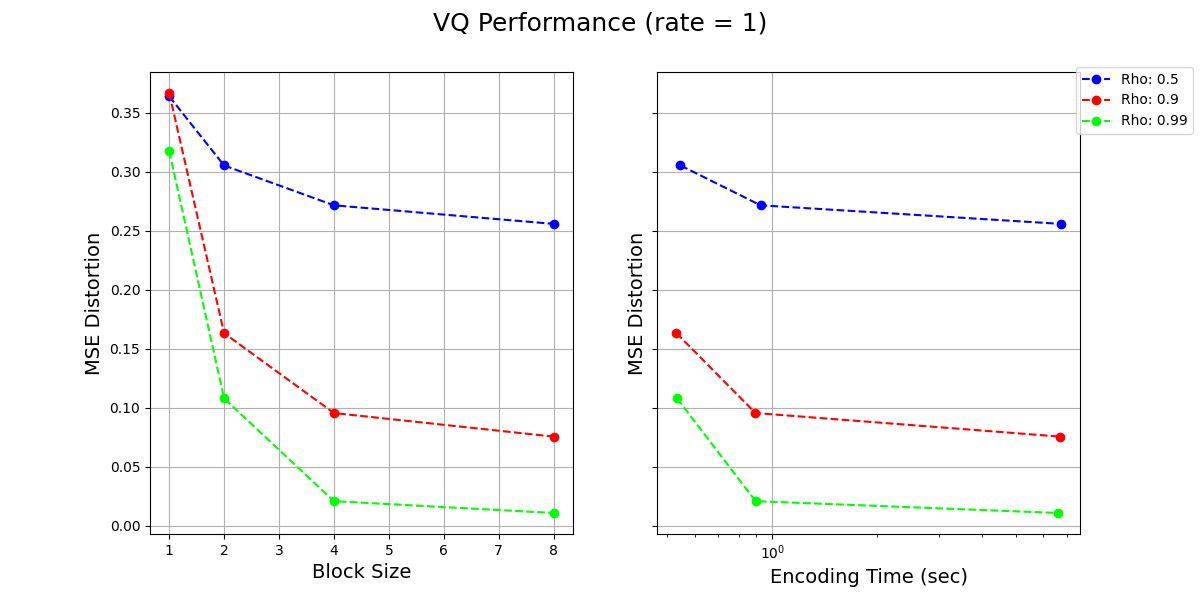
How to read the plots? We fix rate = 1 and use vector quantization. The left plot shows the MSE distortion (y-axis) vs. the block size (x-axis) for different values of . The right plot shows the MSE distortion (y-axis) vs. the Encoding Time (x-axis) for different values of . Note that the points in the second plot correspond to different block sizes which can be inferred based on the matching MSE values from the first plot.
a. [2 points] What is the theoretical distortion limit for at rate of
1 bits per symbol?Solution simplifies into . In class, we learned the rate-distortion function for a gaussian source with variance is When this rate is
1 bit per symbol, we haveb. [4 points] What do you observe as increases for a given ? Comment on the performance and complexity of the encoder as increases. Justify your observations in a few lines.
Solution As seen in the figure, as the block size, , increases, the MSE distortion decreases for a given value of . This is because vector quantization with higher can better exploit the dependence between the consecutive random variables, and also even for independent random variables at higher dimension we can better pack the space and get closer to the optimal rate distortion.
As increases, we expect the time complexity of the encoder to increase as well because the number of codewords increases exponentially with and so does the time for encoding (which needs to search for the nearest codeword).
c. [4 points] Focusing on the left plot, what do you observe as increases? Comment on how the change in performance of the encoder with increasing depends on the value of . Justify your observations in a few lines.
Solution As increases, the series becomes less random and more deterministic. At , the series reduces to . In this case, the MSE distortion is 0. This is because the series is completely deterministic and we can perfectly predict the next value in the series given the previous value.
The bigger is, the bigger difference changing makes. This is because higher (block size) can capture the correlation and hence produce more benefit (as compared to the iid case where higher block size helps but only because of better codeword packing properties).
Q3: Lower Bounds via Information Theory (35 points)
At the annual Claude Shannon rowing contest, there are participants, with out of them having exactly same strength but one of the rowers is exceptionally strong. The contest aims at finding that one strongest rower. The competition organizers are unfortunately limited on the funds, and so want to minimize the number of rounds to declare the winner.
As a world renowned information theorist and compression expert, you have been roped in as a consultant, and have been tasked with deciding the match fixtures so that the exceptionally strong rower can be figured out in minimal number of matches. You have the following information:
- The matches can be between any two teams, where both team consists of an equal number of rowers. E.g. you can decide to have match between Rower 1 and Rower 2, or between (Rower 1, Rower 5) and (Rower 3, Rower 4) or between (Rower 1, Rower 4, Rower 5) and (Rower 2, Rower 3, Rower 6), etc.
- Each match can result in 3 outcomes: either the first team wins, or the second team wins, or it results in a draw. The team with the exceptionally strong rower always wins the match. If both the teams don't contain the strong rower, then the result is always a draw. Thus, the outcome of a fixture is deterministic given the team composition.
- Note that you are allowed to decide the teams in the second match based on the outcome of the first match, i.e. your match-deciding scheme can be adaptive.
- The teams in the matches should be chosen deterministically. They can depend on the outcome of previous matches, but not on any other random variable (e.g., you can't toss a coin to choose the teams!).
-
[10 points] Let the number of players be . Show that you can determine the strongest rower using just 2 matches.
Solution Split the 9 rowers into 3 groups of 3 rowers each. Let's call them , and . The following protocol finds the strongest rower in only two matches: Match 1: vs . - If wins, then we know that the strongest rower is in . Match 2: Choose two rowers from and match them against each other. If the match is a draw, then the third rower is the strongest rower. If one of the rowers wins, then that rower is the strongest rower. Without loss of generality, the same works if wins the first match. - If the result of Match 1 is a draw, then contains the strongest rower. Match 2 can be between any two rowers from , and the result is the same as above.
-
[5 points] Generalize your strategy to rowers. Show that you can find one strongest rower in matches.
Solution The above strategy can be generalized to rowers. We can split the rowers into 3 equal groups of size (if is not divisible by 3, then we set the remaining one or two rowers aside). Then, we implement the above strategy of pitting two of these groups against each other. If the result is a draw, then the third group contains the strongest rower. If one of the groups wins, then it contains the strongest rower. We can recursively apply the same strategy to the winning group. This strategy can be implemented in matches (since we reduce the set of candidates by a factor of at every step). If the strongest rower is in the remainder we set aside, then at worst, we need additional matchs to determine the strongest rower. For large , this is still in .
To get your full fees, you have also been asked to prove that your strategy is indeed the optimal. Let be the random variable representing which player is the stronger rower. is uniformly distributed in the set of all participants
Let be the random variable representing the outcome of the matches you organize.
-
[5 points] Answer the following sub-problems.
- Show that , and for each . When is equality achieved?
- Explain why .
Solution
- because is uniformly distributed over elements. can take on 3 values. To see this consider the match between two teams, which we will call the Cardinal and the Bears. has three outcomes, 1. The Cardinal wins, 2. The Bears win, 3. The match is a draw. The entropy of is maximized when the probability of each outcome is equal, so where equality is achieved if the cases 1, 2, and 3 are equally likely.
- because the outcome of each match is deterministic given the strongest rower. If we know the strongest rower, then we know the outcome of each match. So, given the strongest rower, , there is no uncertainty in the outcomes of the matches.
-
[10 points] We want to show that we will at least need matches to determine the strongest rower.
- Show that we can determine the strongest rower from matches, if and only if .
- Using the sub-problem above, show that matches are required to determine the strongest rower. Thus, proving that the scheme in Q4.1 is indeed optimal! (HINT: think about using , and its properties).
Solution
- If , then is completely determined given . This means that we can determine the strongest rower from matches. For the inverse direction, if we can determine the strongest rower from matches, then is completely determined given . This means that .
- The mutual information is:
We know that , so we can re-order the above equality to get:
As shown in the previous sub-problem, we can only find the strongest rower from matches if , so any winning strategy will have:
From part 3 above, we know that and for all , so we have . Yielding,
So,
Therefore, at least matches are required to determine the strongest rower.
-
[5 points] Let's get back to the rowers scenario. To simplify the logistics, the organizers wanted to pre-decide what the matches are going to be, even before the contest began. That is, the teams for the th match are pre-decided, and do not depend upon the outcome of the first matches. In other words the match deciding strategy is non-adaptive. Show that even in this non-adaptive case, you can find the strongest rower using the outcome of 2 pre-decided matches!
Solution For the first round, we split the 9 rowers into 3 groups of 3 rowers each. Then, in the second round, we create 3 new groupings of 3 where no rower has a teammate that they had in the first round. For example, labeling the rowers 1 through 9, one possible arraingement could be:
- Round 1: (1,2,3), (4,5,6), (7,8,9)
- Round 2: (1,4,7), (2,5,8), (3,6,9)
Ahead of time, we can randomly select two teams from this grouping to race each other in each round (e.g., we could do (1,2,3) vs. (4,5,6) and (1,4,7) vs. (3,6,9)). If a team wins a round, we know it contains the strongest rower, or in the case of a tie, we know that the third team contains the strongest rower. Since the teams consist of unique rowers the team we identify from Round 1 as containing the strongest rower will only have one rower in common with the team we identify from the second round as containing the strongest rower, allowing us to uniquely identify their identity!
Q4: Image Compression (40 points)
This question is about image compression. We will implement the transform coding ideas and use it to build a simple image compression scheme. Here are the instructions for this question:
- We have provided the code for this question both in the SCL HW repo as
EE274_HW4_ImageCompressor.ipynbas well as a Google Colab notebook. - We have tested the code on the Colab notebook, and we recommend working on the Colab notebook for this question. You should make a copy of the Colab notebook and work on the copy.
- The question has both coding and written parts. The written parts should be answered in the Colab notebook itself. You will need to run this notebook on Google Colab to answer some of the written parts.
- After working on the Colab notebook, you should download the notebook as a
.ipynbfile and submit it on Gradescope by replacing the existingEE274_HW4_ImageCompressor.ipynbfile. This will be graded manually.
Solution Solution Notebook
Q5: HW4 Feedback (5 points)
Please answer the following questions, so that we can adjust the difficulty/nature of the problems for the next HWs.
- How much time did you spent on the HW in total?
- Which question(s) did you enjoy the most?
- Are the programming components in the HWs helping you understand the concepts better?
- Did the HW4 questions complement the lectures?
- Any other comments?